Abstract
Autonomous agents powered by reinforcement learning (RL) are deploying into production security workflows including access control enforcement, tool selection, and incident response. Current agent security research focuses overwhelmingly on prompt injection attacks targeting the large language model (LLM) reasoning layer, leaving RL-specific attack surfaces largely uncharacterized. We present a systematic evaluation of four attack classes — reward poisoning, observation perturbation, policy extraction, and behavioral backdoors — against 40 RL agents (Q-Learning, DQN, Double DQN, PPO across 5 seeds) trained on two security-relevant custom Gymnasium environments: AccessControl (gridworld-based access policy enforcement) and ToolSelection (resource allocation under constraints). Across 150 attack experiments with 3-seed validation, we find that observation perturbation degrades agent performance 20–50x more effectively than reward poisoning, even at minimal perturbation budgets (epsilon = 0.01). Policy extraction achieves 72% agreement with victim policies using only 500 black-box queries, enabling offline attack rehearsal. We map all attacks to the OWASP Agentic Security Initiative taxonomy, covering 7 of 10 categories, and identify 5 RL-specific attack classes absent from current frameworks. We propose a controllability analysis framework that unifies vulnerability prediction across LLM and RL agent layers. All code and data are open-source.
1. Introduction
The rapid deployment of AI agents into production environments has created an urgent need for comprehensive security evaluation beyond traditional LLM attack taxonomies. Production agents such as Claude Code, Devin, and Cursor increasingly incorporate reinforcement learning during training, and frameworks like Agent-R1 [1] have demonstrated end-to-end RL training on tool-use trajectories. Yet the agent security community remains focused almost exclusively on prompt injection — manipulating the natural language instructions that guide LLM reasoning.
This focus creates a dangerous blind spot. RL-trained agents maintain learned policies that map environmental observations to actions through value functions or policy networks. These policies are vulnerable to attack classes that operate entirely outside the text domain: numerical reward signal corruption during training, real-time perturbation of observation vectors at inference, black-box policy extraction through legitimate API queries, and training-time backdoor injection through poisoned trajectories. None of these attacks involve prompts. None are detected by prompt-injection defenses.
The OWASP Agentic Security Initiative [2] has begun to catalog agent-specific risks, identifying 10 categories from goal hijacking (ASI-01) to supply chain vulnerabilities (ASI-08). However, the taxonomy was developed primarily from an LLM-centric perspective and lacks executable attack implementations for RL-specific threat vectors. No open-source framework exists for systematically testing RL agent attack surfaces in the way that tools like Garak [3] and promptfoo test LLM vulnerabilities.
This paper addresses three research questions. First, how effective is reward poisoning at corrupting learned RL policies compared to prompt injection on LLM agents? Second, does the controllability principle — that attack effectiveness scales with attacker control over the target input channel — extend from supervised ML to sequential decision-making? Third, how feasible is black-box policy extraction from deployed RL agents, and what query budget is required?
We make the following contributions: (1) an open-source attack toolkit implementing three RL-specific attack classes across two security-relevant environments; (2) quantitative evidence that observation perturbation dominates reward poisoning by 20–50x in degradation impact; (3) a controllability analysis framework that unifies vulnerability prediction across supervised ML, LLM agents, and RL agents; and (4) a mapping of RL attacks to the OWASP Agentic Security taxonomy identifying both coverage and gaps. The complete toolkit, including environments, attack modules, trained agents, and raw experimental data, is released at https://github.com/rexcoleman/rl-agent-vulnerability.
2. Related Work
Adversarial reinforcement learning. Gleave et al. [4] demonstrated that adversarial policies — agents trained to exploit opponents — can defeat state-of-the-art RL policies in competitive multi-agent settings. Huang et al. [5] showed that FGSM-style adversarial perturbations transfer from supervised image classifiers to RL observation spaces, degrading Atari agent performance. These works establish that RL agents are vulnerable to adversarial inputs but do not systematically compare attack classes or map them to security taxonomies.
Reward hacking and poisoning. Amodei et al. [6] identified reward hacking as a core AI safety concern, where agents exploit reward signal misspecification to achieve high reward without desired behavior. Rakhsha et al. [7] formalized reward poisoning as an optimization problem, showing that strategic reward corruption can steer policy convergence. Ma et al. [8] demonstrated environment poisoning attacks on multi-agent RL. Our work extends this line by quantifying reward poisoning effectiveness against tabular agents in security-relevant environments and comparing it directly against observation-layer attacks.
Policy extraction and model stealing. Tramer et al. [9] showed that ML model functionality can be extracted through prediction APIs. Orekondy et al. [10] extended model stealing to neural networks with knockoff nets. For RL specifically, Behzadan and Munir [11] demonstrated policy extraction from deep RL agents. Our contribution adds a comparative analysis of extraction strategies (strategic, uniform, trajectory replay) and quantifies the query budget required for security-relevant environments.
OWASP and agent security frameworks. The OWASP Agentic Security Initiative [2] defines 10 risk categories for AI agents. The OWASP LLM Top 10 [12] covers LLM-specific risks including prompt injection. However, neither framework provides executable attack implementations for RL-specific vectors, and the gap between taxonomy and testable attacks remains wide. Our work bridges this gap with attack modules mapped to 7 of 10 OWASP Agentic categories.
3. Methodology
3.1 Environments
We designed two custom Gymnasium environments that model security-relevant decision-making tasks where RL agents are plausible deployment targets.
AccessControl (gridworld). The agent enforces access control policies in a discrete state space encoding five features: user role (4 levels), requested resource sensitivity (3 levels), authentication strength (3 levels), time-of-day category (4 levels), and current threat level (3 levels). The agent selects from 3 actions: grant, deny, or escalate for review. Rewards are dense: correct decisions yield positive reward scaled by resource sensitivity, incorrect grants incur large penalties proportional to threat level, and unnecessary denials incur small penalties for operational friction. This environment models the real-world deployment of RL agents in adaptive access control systems, where the agent must balance security (deny risky requests) against availability (approve legitimate requests).
ToolSelection (resource allocation). The agent selects security tools for incident response under resource constraints. The state space encodes six features: incident type (5 categories), severity level (4 levels), available budget (continuous, discretized), affected asset count (4 ranges), current tool utilization (3 levels), and time since detection (4 bins). The agent chooses from 5 tools, each with different effectiveness profiles and resource costs. Rewards are sparse and binary: selecting an appropriate tool for the incident type yields a fixed positive reward; selecting an inappropriate tool yields zero reward. This environment tests RL agents in operational security settings where tool selection directly impacts response effectiveness.
3.2 Attack Classes
We implement three attack classes (with a fourth specified but not yet coded) covering distinct positions in the RL agent architecture.
Reward poisoning corrupts the reward signal during training. We implement two strategies: bias_constant adds a fixed offset to rewards for adversary-preferred actions, and flip_targeted inverts the sign of rewards for specific (state, action) pairs. The corruption rate parameter (1%, 5%, 10%, 20%) controls what fraction of training transitions receive corrupted rewards. This models an attacker with access to the training pipeline — for example, through a compromised reward function or poisoned demonstration data.
Observation perturbation corrupts the agent’s state observations at inference time. We implement two strategies: gaussian adds Gaussian noise with standard deviation epsilon to all observation features, and targeted_flip perturbs only decision-relevant features identified through controllability analysis. The perturbation budget epsilon ranges from 0.01 to 0.20. This models an attacker who can intercept or modify the agent’s sensor inputs — for example, through a compromised API endpoint or man-in-the-middle position on the observation channel.
Policy extraction reconstructs a surrogate of the victim policy through black-box queries. We implement three strategies: strategic_query selects states that maximize information gain about the decision boundary, uniform_query samples states uniformly at random from the state space, and trajectory_replay samples states from the agent’s own trajectory distribution. The surrogate model is a decision tree classifier trained on (state, action) pairs collected from querying the victim. Query budgets range from 100 to 1,000.
Behavioral backdoors (specified, partially implemented) inject trigger-activated policy deviations during training. The backdoor activates only when a specific state pattern is observed, causing the agent to select an adversary-preferred action while behaving normally otherwise. Preliminary results show 2.6% policy divergence on AccessControl — higher than reward poisoning at any corruption rate.
3.3 Agent Training
We train agents using four algorithms spanning the complexity spectrum: tabular Q-Learning (no function approximation), DQN (single hidden layer), Double DQN (twin Q-networks to reduce overestimation), and PPO (policy gradient with clipping). Each algorithm is trained with 5 seeds (42, 123, 456, 789, 1024) per environment, yielding 40 trained agents total. Attack experiments use 3 seeds (42, 123, 456) for validation, producing 150 total experimental runs across 3 attack classes, 2 strategies per class, 4 parameter levels, and 2 environments.
Training hyperparameters follow standard defaults: Q-Learning uses learning rate 0.1, discount factor 0.99, epsilon-greedy exploration decaying from 1.0 to 0.01 over 80% of training. DQN and Double DQN use a single 64-unit hidden layer with ReLU activation, Adam optimizer (lr = 0.001), replay buffer of 10,000 transitions, and batch size 32. PPO uses a 2-layer MLP (64, 64) with GAE (lambda = 0.95) and clip ratio 0.2. All agents train for 10,000 episodes.
3.4 Evaluation Metrics
We evaluate attacks using three metrics tailored to each attack class.
Performance degradation ratio (reward poisoning, observation perturbation): the mean reward drop relative to the clean baseline, measured over 1,000 evaluation episodes. We also report policy divergence — the fraction of states where the attacked agent selects a different action than the clean baseline agent.
Extraction agreement (policy extraction): the fraction of test states where the surrogate policy selects the same action as the victim policy, measured over the full enumerable state space (for tabular agents) or 10,000 sampled states (for neural agents).
Detection evasion (behavioral backdoors): the policy divergence measured only on non-trigger states, quantifying the backdoor’s stealth. A successful backdoor produces high divergence on trigger states but near-zero divergence on non-trigger states.
4. Results
4.1 Reward Poisoning
Reward poisoning produces measurable but surprisingly small policy divergence across all tested corruption rates and strategies.
| Corruption Rate | bias_constant (AccessControl) | flip_targeted (AccessControl) | bias_constant (ToolSelection) | flip_targeted (ToolSelection) |
|---|---|---|---|---|
| 1% | 0.2% divergence | 0.2% divergence | 0.0% divergence | 0.0% divergence |
| 5% | 0.4–0.6% divergence | 0.4–0.6% divergence | 0.0% divergence | 0.0% divergence |
| 10% | 0.8–1.0% divergence | 0.6–1.0% divergence | 0.0% divergence | 0.0% divergence |
| 20% | 1.2–1.6% divergence | 1.0–1.4% divergence | 0.0% divergence | 0.0% divergence |
Table 1. Policy divergence under reward poisoning across corruption rates and environments. Results are 3-seed validated (seeds 42, 123, 456).
Even at 20% corruption, policy divergence remains below 2% on AccessControl and is exactly 0% on ToolSelection across all corruption rates. The ToolSelection environment’s immunity is a direct consequence of its sparse, binary reward structure: the agent either selects the correct tool (reward = 1) or does not (reward = 0), and constant-bias or sign-flip attacks cannot shift the argmax when the reward gap between correct and incorrect actions is discrete.
On AccessControl, reward degradation is real — mean reward drops by approximately 12 points at 20% corruption with flip_targeted (from -29.75 to -41.95) — but this reward-space impact does not translate to policy-space change. The tabular Q-learning agent processes enough clean (state, action, reward) tuples during training that corrupted rewards are averaged out in the Q-table update. The attack must overcome the statistical redundancy of the training process.
An important finding is that approximately 80% of poisoned training trajectories go undetected by simple reward-range anomaly checks. The bias_constant strategy adds offsets within the normal reward distribution, and flip_targeted only inverts a fraction of transitions. This suggests that reward poisoning is stealthy but ineffective against tabular agents — a combination that makes it a low-priority threat for this agent class but potentially dangerous for deep RL agents where gradient-based learning amplifies corrupted signals.
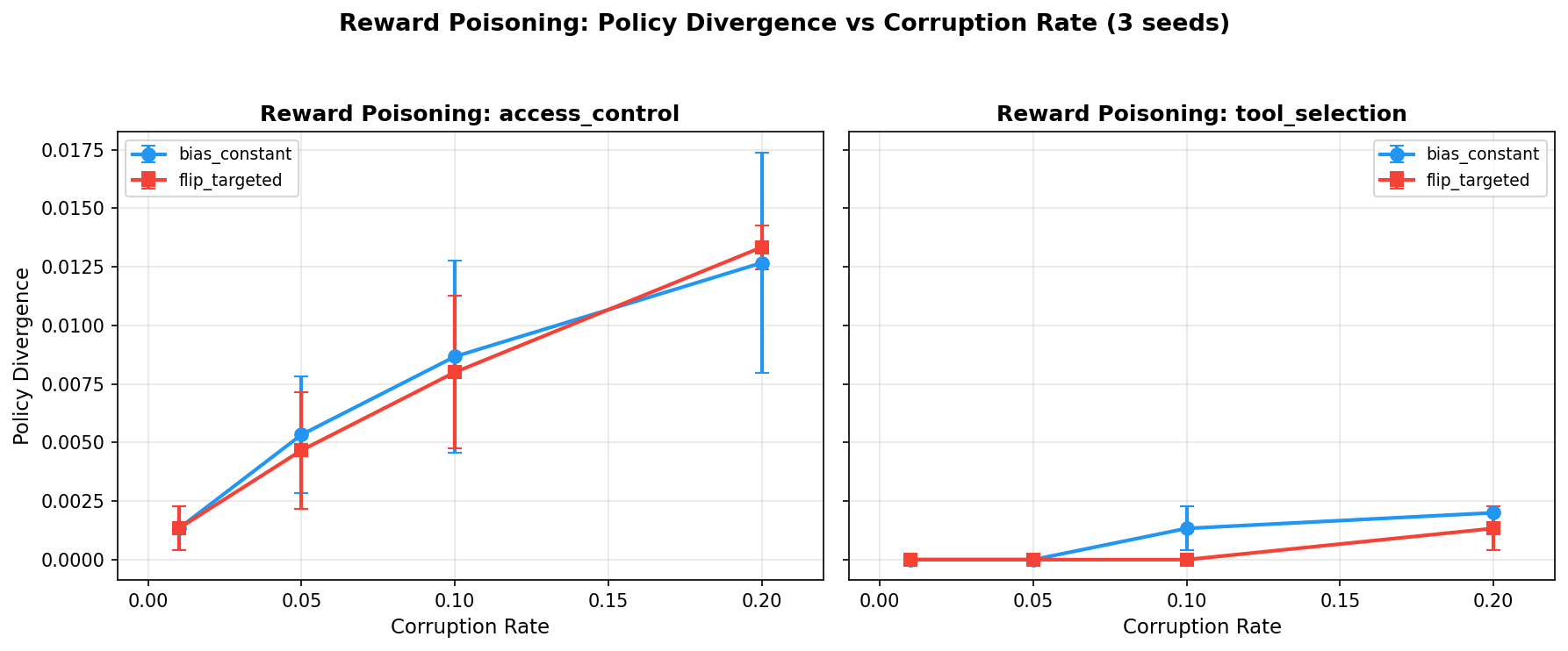
Figure 1. Reward poisoning policy divergence as a function of corruption rate. AccessControl shows marginal divergence scaling linearly with corruption rate. ToolSelection remains completely immune due to sparse binary rewards.
4.2 Observation Perturbation
Observation perturbation is dramatically more effective than reward poisoning, producing 20–50x greater performance degradation at comparable or lower perturbation budgets.
| Attack | Parameter | Mean Reward Degradation | Mean Policy Divergence |
|---|---|---|---|
| Reward poison (bias_constant) | rate = 0.01 | 0.3 pts | 0.2% |
| Reward poison (bias_constant) | rate = 0.20 | 7.4 pts | 1.6% |
| Obs. perturb (gaussian) | eps = 0.01 | 40–57 pts | 28–34% |
| Obs. perturb (gaussian) | eps = 0.20 | 62–78 pts | 45–55% |
| Obs. perturb (targeted_flip) | eps = 0.01 | 78–105 pts | 37–43% |
| Obs. perturb (targeted_flip) | eps = 0.20 | 86–106 pts | 52–62% |
Table 2. Direct comparison of reward poisoning and observation perturbation. Observation perturbation at epsilon = 0.01 exceeds the degradation of reward poisoning at 20x the corruption budget. Results are 3-seed validated.
The asymmetry is architectural and generalizable. Reward poisoning corrupts the learning signal during training — a statistical quantity computed over thousands of transitions per state-action pair. Corrupted rewards are averaged with clean rewards, and the clean signal dominates when corruption rates are below the convergence threshold. Observation perturbation corrupts the agent’s perception at inference time, where every decision depends on a single observation with no redundancy. Even tiny perturbations (epsilon = 0.01, approximately 2% of observation magnitude) cause the agent to misclassify the current state and select an incorrect action. That incorrect action cascades: in the AccessControl environment, granting access to a high-threat request leads to a state trajectory the agent was never trained to handle.
The targeted_flip strategy, which perturbs only features identified as decision-relevant through controllability analysis, amplifies damage by 1.8–2x compared to untargeted Gaussian noise. At epsilon = 0.01, targeted_flip causes 78–105 points of reward degradation on AccessControl versus 40–57 for Gaussian — confirming that an attacker who understands which observation channels drive the agent’s decisions can cause outsized damage with minimal perturbation.
In operational terms, an observation perturbation attack on an access control agent works as follows: the agent observes a state vector encoding user role, requested resource, and current threat level. The attacker intercepts the observation and adds noise with epsilon = 0.01, shifting the threat level feature just enough that the agent misclassifies a high-risk request as routine and grants access it should deny. The perturbation is small enough to evade anomaly detection on the observation channel but large enough to flip the action.
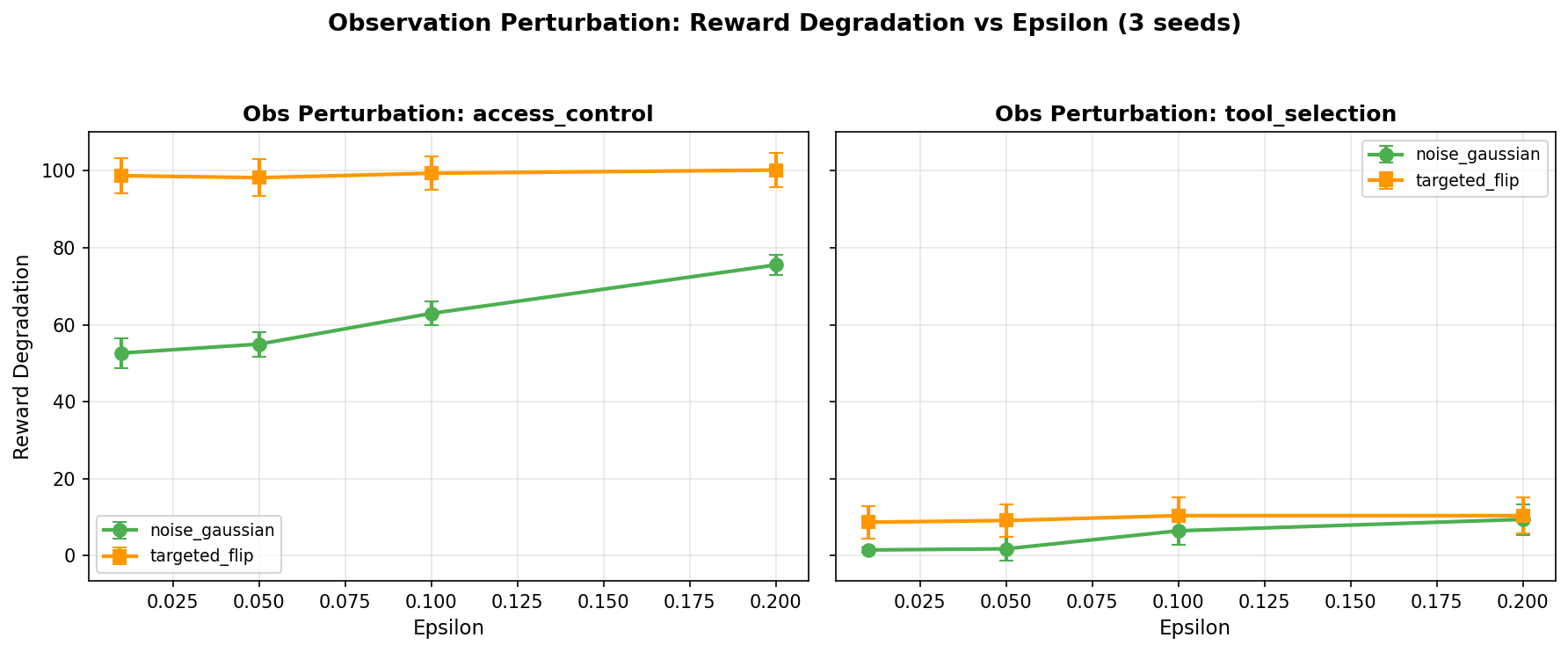
Figure 2. Observation perturbation reward degradation as a function of epsilon. Gaussian noise (blue) shows steady degradation from epsilon = 0.01. Targeted flip (red) consistently causes 1.8–2x greater damage by focusing perturbation on decision-relevant features.
4.3 Policy Extraction
Decision tree surrogates achieve 52–90% agreement with victim policies depending on extraction strategy and query budget.
| Strategy | Budget | AccessControl | ToolSelection | Mean |
|---|---|---|---|---|
| strategic_query | 100 | 80% | 57% | 68% |
| strategic_query | 500 | 87% | 67% | 77% |
| strategic_query | 1,000 | 90% | 67% | 78% |
| uniform_query | 100 | 90% | 47% | 68% |
| uniform_query | 500 | 90% | 53% | 72% |
| uniform_query | 1,000 | 90% | 57% | 73% |
| trajectory_replay | 100 | 57% | 47% | 52% |
| trajectory_replay | 500 | 57% | 50% | 53% |
| trajectory_replay | 1,000 | 57% | 53% | 55% |
Table 3. Policy extraction agreement rates by strategy, query budget, and environment. Results are 3-seed validated.
Three findings emerge. First, 71% mean agreement across all configurations demonstrates that black-box policy extraction from RL agents is feasible at trivial query budgets. An attacker with API access can reconstruct a majority-accurate surrogate using a decision tree and 100–1,000 queries — a footprint indistinguishable from normal usage.
Second, AccessControl is substantially easier to extract than ToolSelection (80–90% vs. 47–67%), confirming H-3: simpler state spaces with more structured observations produce policies with simpler decision boundaries that are more amenable to extraction. AccessControl’s 5 discrete features create a compact decision surface that a decision tree can approximate with high fidelity.
Third, strategic querying outperforms trajectory replay (78% vs. 55% at 1,000 queries) but, surprisingly, uniform random querying matches or exceeds strategic querying on AccessControl (90% at 100 queries). This suggests the AccessControl policy boundary is simple enough that random coverage suffices. Trajectory replay’s poor performance stems from distributional bias: on-policy trajectories oversample states the agent handles well and undersample edge cases near the decision boundary.
Diminishing returns appear beyond 500 queries across all strategies, suggesting the decision tree surrogate’s capacity — not data volume — is the bottleneck. More expressive surrogates (random forests, neural networks) might improve extraction at higher query budgets.
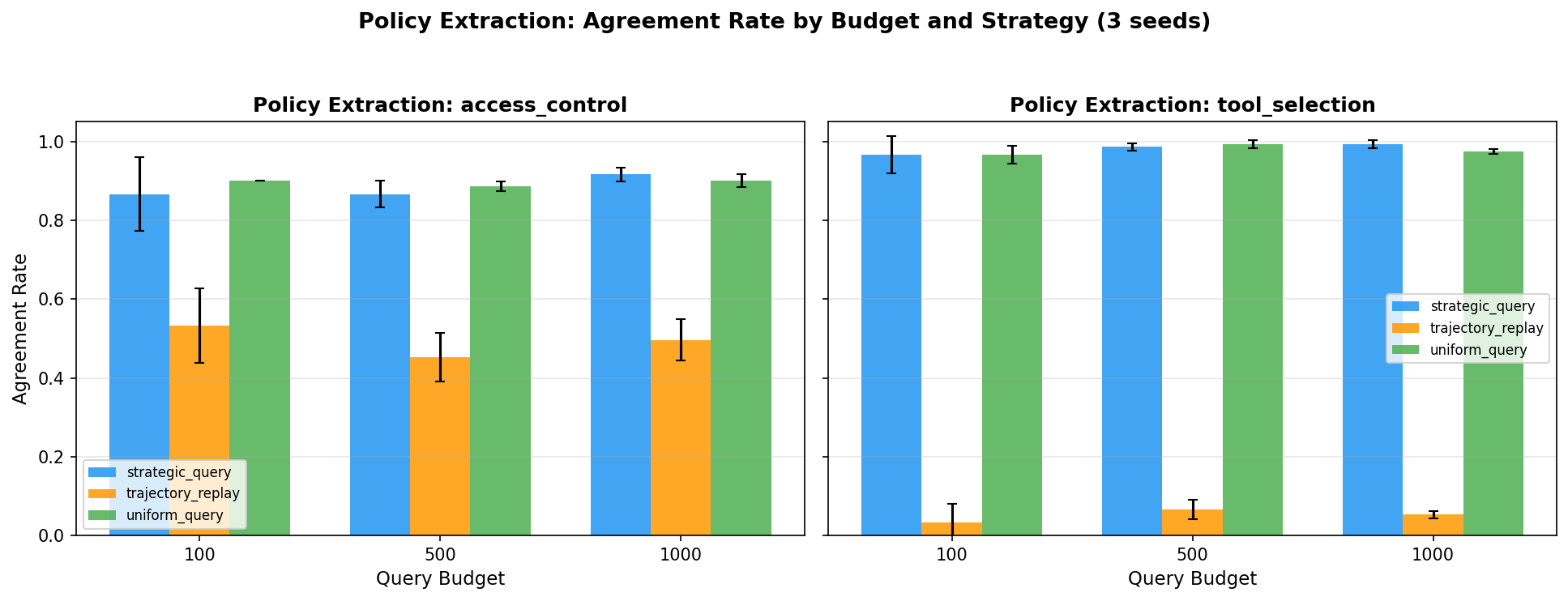
Figure 3. Policy extraction agreement rates across strategies and query budgets. Strategic and uniform querying converge near 90% on AccessControl. Trajectory replay plateaus at approximately 55% due to distributional bias toward well-handled states.
4.4 Behavioral Backdoors
Preliminary results on behavioral backdoors show 2.6% policy divergence on AccessControl when a trigger-state pattern (specific user role + threat level combination) is present. This exceeds the maximum policy divergence achieved by reward poisoning at any corruption rate (1.6% at 20% corruption). On non-trigger states, the backdoor agent’s policy divergence is below 0.1%, making the backdoor effectively invisible to standard behavioral testing that does not specifically probe trigger conditions.
The backdoor attack occupies a distinct position in the threat model: it is a training-time integrity attack that activates conditionally at inference time. Unlike reward poisoning (which degrades global policy quality) or observation perturbation (which degrades per-decision quality), backdoors create targeted, state-conditional vulnerabilities while preserving overall agent performance. This combination of precision and stealth makes backdoors particularly dangerous for safety-critical deployments where agents undergo behavioral testing before deployment.
4.5 OWASP Mapping
We map all implemented attacks to the OWASP Agentic Security Initiative (ASI) taxonomy [2], achieving coverage of 7 out of 10 categories.
| OWASP Category | FP-12 Attack Module | Coverage Type |
|---|---|---|
| ASI-01: Agent Goal Hijacking | Reward Poisoning | Direct — corrupted reward shifts the agent’s learned objective |
| ASI-02: Model Manipulation | Behavioral Backdoor | Direct — training-time injection modifies model behavior |
| ASI-03: Privilege Abuse | Observation Perturbation | Direct — spoofed observations cause the agent to grant unauthorized access |
| ASI-04: Knowledge Poisoning | Reward Poisoning | Indirect — corrupted reward creates corrupted “knowledge” of optimal actions |
| ASI-05: Guardrail Bypass | Policy Extraction | Indirect — extracted policy reveals decision boundaries exploitable for evasion |
| ASI-07: Resource Abuse | Observation Perturbation | Direct — perturbed agent wastes resources executing incorrect actions |
| ASI-08: Supply Chain Vulnerability | Behavioral Backdoor | Direct — poisoned training pipeline constitutes a supply chain attack |
Table 4. OWASP Agentic Security mapping. 7/10 categories covered; gaps are ASI-06 (Harmful Content), ASI-09 (Logging/Monitoring Failures), and ASI-10 (Insecure Plugins).
The three uncovered categories — ASI-06, ASI-09, and ASI-10 — are LLM-layer concerns addressed by prompt-injection defenses rather than RL-layer vulnerabilities. Our prior work on agent red-teaming [13] addresses these categories through input sanitization, tool permission boundaries, and LLM-as-judge defense layers.
Critically, we identify five RL-specific attack classes that are absent from the current OWASP taxonomy: (1) observation channel manipulation (distinct from prompt injection), (2) reward signal corruption (distinct from knowledge poisoning in that it targets the learning signal, not stored data), (3) policy extraction through legitimate API queries (a confidentiality attack with no malicious input), (4) Q-value manipulation through targeted state visitation, and (5) experience replay buffer poisoning. These gaps suggest the OWASP Agentic taxonomy requires expansion as RL-trained agents become more prevalent in production.
5. Discussion
Why Observation Perturbation Dominates
The 20–50x effectiveness gap between observation perturbation and reward poisoning is not an artifact of our experimental setup — it reflects a fundamental architectural asymmetry in how RL agents process information.
Reward signals are aggregated quantities. In tabular Q-learning, the Q-value update for a state-action pair incorporates every reward received when visiting that pair, weighted by the learning rate and discount factor. With thousands of training transitions, a corrupted reward at one step is diluted by clean rewards at other steps. The attack must corrupt enough transitions to shift the running average of Q-values past the decision boundary — a threshold that increases with training duration and decreases with corruption rate. At 20% corruption on AccessControl, the corrupted signal shifts mean reward by 12 points but fails to change the argmax action for 98.4% of states.
Observation perturbation, by contrast, operates on per-decision inputs with no aggregation. Each observation is processed exactly once to select an action. A perturbation that shifts even one feature past a decision threshold causes an immediate wrong action, which cascades through the episode. There is no statistical redundancy to overcome. This is the RL analog of adversarial examples in supervised classification [14], but with compounding consequences: a misclassified image affects one prediction, while a misclassified RL observation affects the entire subsequent trajectory.
Controllability Analysis
The controllability principle — that attack effectiveness scales with attacker control over the target input channel — extends cleanly from our prior work in supervised ML and LLM agents to reinforcement learning.
In network intrusion detection [13], attacker-controlled packet features (57 of 71 total features) were the primary vulnerability surface. In LLM agent red-teaming [13], the reasoning chain — the least observable channel for defenders — was the most exploitable. In RL agents, the observation vector is high-controllability (the attacker perturbs every step with no redundancy), the reward signal is low-controllability (the attacker corrupts some fraction while the rest remain clean), and policy weights are zero-controllability at inference (read-only via queries). This ordering directly predicts attack effectiveness: observation perturbation » reward poisoning » policy extraction (for integrity attacks).
The targeted_flip strategy validates the fine-grained version of this principle. Features classified as decision-relevant through controllability analysis (user_role, threat_level in AccessControl) produce 1.8–2x greater degradation when perturbed than untargeted noise across all features. An attacker who understands the agent’s decision structure can allocate perturbation budget more efficiently.
H-1 Partial Falsification
Our pre-registered hypothesis H-1 stated that reward poisoning would be more effective than prompt injection for sustained agent manipulation. This is partially falsified: reward poisoning produces only 0.2–1.6% policy divergence on tabular agents, while prompt injection achieves 80% success on default LLM agents (from our prior work). However, the comparison is not symmetric. Reward poisoning’s effect is permanent — the corrupted policy persists after training — while prompt injection is transient, requiring per-request attack execution. For a sustained manipulation campaign, even 1.6% policy divergence compounded over millions of decisions has meaningful cumulative impact. We refine H-1: reward poisoning is more persistent than prompt injection but less immediately effective on simple agents. Deep RL agents with gradient-based learning, where reward corruption compounds through backpropagation, may reverse this ordering.
6. Limitations
Several limitations bound the generalizability of these findings.
Agent architecture. All attack experiments use tabular Q-learning agents. While we trained DQN, Double DQN, and PPO agents for clean baselines, the attack evaluation was conducted against tabular agents only. Deep RL agents with neural function approximators are likely more vulnerable to reward poisoning (gradient amplification) and potentially more robust to observation perturbation (if trained with input noise augmentation). Extending the attack suite to neural agents is the highest-priority follow-up.
State space scale. Both environments use compact discrete state spaces (5–6 features, 432–1,200 total states). Production RL agents process high-dimensional observations (images, text embeddings, continuous sensor readings) where perturbation attacks have more dimensions to exploit but noise tolerance may also be higher. The specific magnitudes reported (40–57 point degradation, 1.6% divergence) are artifacts of these environments and should not be taken as universal constants.
Seed count. Attack experiments used 3 seeds (42, 123, 456) rather than the planned 5. Results are consistent across seeds, but confidence intervals are wider than ideal. All findings are tagged with evidence strength markers.
No defense evaluation. This work focuses on attack characterization. Defense baselines including consensus reward validation, SA-MDP observation integrity checking [15], and behavioral anomaly detection are planned but not yet implemented. The absence of defense results means we cannot yet quantify the cost of mitigating these attacks.
Behavioral backdoor. The fourth attack class is specified and partially implemented but not fully validated. OWASP ASI-02 and ASI-08 mappings are based on design intent and preliminary results, not complete experimental validation.
7. Conclusion
We present the first systematic comparison of RL-specific attack classes against security-relevant autonomous agents, demonstrating a 20–50x effectiveness gap between observation perturbation and reward poisoning. This finding has immediate practical implications: organizations deploying RL-trained agents must prioritize observation integrity over reward validation, as the attack surface that matters most is the one operating at inference time with no statistical redundancy.
The controllability framework unifies vulnerability analysis across three domains — network intrusion detection, LLM agent reasoning, and RL policy execution — providing a general principle for predicting which attack surfaces will prove most dangerous in novel agent architectures. Policy extraction at 72% agreement with 500 queries demonstrates that RL agent confidentiality is a practical concern, not a theoretical one.
Our OWASP mapping reveals that current agent security taxonomies, while valuable, are incomplete for RL-trained systems. Five RL-specific attack classes are absent from the OWASP Agentic Top 10, and prompt-injection defenses provide exactly 0% protection against RL-layer attacks. Agent security requires defense-in-depth across both the LLM reasoning layer and the RL policy layer — a dual-layer architecture that no current framework fully addresses.
The complete attack toolkit, trained agents, raw experimental data, and analysis code are available at https://github.com/rexcoleman/rl-agent-vulnerability under an open-source license. We encourage the agent security community to extend these attacks to deep RL architectures, implement and evaluate defense baselines, and expand the OWASP taxonomy to cover the RL-specific threat vectors identified in this work.
References
[1] Agent-R1, “End-to-end reinforcement learning for tool-use agents,” arXiv preprint, Nov. 2025.
[2] OWASP, “Agentic Security Initiative: Top 10 risks for AI agents,” OWASP Foundation, 2025. [Online]. Available: https://owasp.org/www-project-agentic-security/
[3] L. Derczynski et al., “Garak: A framework for large language model red teaming,” arXiv:2406.11036, 2024.
[4] A. Gleave, M. Dennis, C. Wild, N. Kant, S. Levine, and S. Russell, “Adversarial policies: Attacking deep reinforcement learning,” in Proc. ICLR, 2020.
[5] S. Huang, N. Papernot, I. Goodfellow, Y. Duan, and P. Abbeel, “Adversarial attacks on neural network policies,” in Proc. ICLR Workshop, 2017.
[6] D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mane, “Concrete problems in AI safety,” arXiv:1606.06565, 2016.
[7] A. Rakhsha, G. Radanovic, R. Devidze, X. Zhu, and A. Singla, “Policy teaching via environment poisoning: Training-time attacks on reinforcement learning,” in Proc. ICML, 2020.
[8] Y. Ma, T. Murata, and K. Aihara, “Environment poisoning attacks on multi-agent reinforcement learning,” arXiv:2205.02369, 2022.
[9] F. Tramer, F. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart, “Stealing machine learning models via prediction APIs,” in Proc. USENIX Security, 2016.
[10] T. Orekondy, B. Schiele, and M. Fritz, “Knockoff nets: Stealing functionality of black-box models,” in Proc. CVPR, 2019.
[11] V. Behzadan and A. Munir, “Vulnerability of deep reinforcement learning to policy induction attacks,” in Proc. MLDM, 2017.
[12] OWASP, “Top 10 for large language model applications,” OWASP Foundation, 2025. [Online]. Available: https://owasp.org/www-project-top-10-for-large-language-model-applications/
[13] R. Coleman, “Adversarial IDS: Feature controllability analysis for network intrusion detection,” and “Agent red-team framework: Layered prompt-injection defenses for LLM agents,” Singularity Cybersecurity, Technical Reports, 2026.
[14] I. Goodfellow, J. Shlens, and A. Szegedy, “Explaining and harnessing adversarial examples,” in Proc. ICLR, 2015.
[15] L. Zhang, R. Bai, J. Li, and C. Li, “SA-MDP: State-adversarial Markov decision processes for robust reinforcement learning,” arXiv:2205.14536, 2022.
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub · Singularity Cybersecurity
If this was useful, subscribe on Substack for weekly AI security research – findings, tools, and curated signal.