Abstract
Autonomous AI agents that reason, use tools, and take actions are being deployed into production systems at scale, yet no systematic methodology exists for evaluating their security posture beyond the model layer. We present an open-source red-team framework that executes 19 attack scenarios across 7 attack classes against LangChain ReAct agents with a Claude Sonnet backend. Five of the seven attack classes target agent-specific surfaces not covered by OWASP LLM Top 10 or MITRE ATLAS. Our most significant finding is reasoning chain hijacking, an attack that exploits an agent’s core capability — following structured multi-step plans — as the attack vector, achieving a 100% success rate against default-configured agents across 3 seeds (temperature=0). We introduce adversarial control analysis (ACA) to the agent security domain and demonstrate that attack success correlates inversely with defender observability: the reasoning chain, being internal to the agent’s processing loop, is both the least observable input and the most vulnerable surface. A layered defense architecture (input sanitization, LLM-as-judge, tool permission boundaries) achieves 67% average attack reduction, but reasoning chain hijacking remains the highest-priority unsolved problem, decreasing only from 100% to 33% success. The framework, attack taxonomy, and all scenarios are released as open source to enable reproducible agent security evaluation.
1. Introduction
The autonomous AI agent market is projected to reach $8 trillion in commerce by 2030 [1], with agent frameworks like LangChain, CrewAI, and AutoGen enabling rapid deployment of systems that reason over tools, maintain persistent memory, and delegate tasks across multi-agent hierarchies. Yet security evaluation of these systems remains almost entirely focused on the underlying language model — prompt injection defenses, alignment techniques, and output filtering — rather than the agent layer where tool orchestration, reasoning chains, and cross-agent communication introduce fundamentally different attack surfaces.
This gap is consequential. The GDPval benchmark reports 50% task-level parity between AI and human performance, while Scale AI’s Realistic Linguistics Index measures only 4.17% project-level completion — a roughly 12x deployment gap [2]. As organizations bridge this gap by deploying agents into production workflows, the attack surface expands from model-level vulnerabilities (what the LLM says) to agent-level vulnerabilities (what the agent does). An agent that can search files, write to storage, and execute multi-step plans is categorically more dangerous when compromised than a chatbot that can only generate text.
Existing security frameworks address portions of this problem space. OWASP’s Top 10 for LLM Applications covers prompt injection (LLM01), insecure output handling (LLM02), and training data poisoning (LLM03), among others [3]. MITRE ATLAS catalogs adversarial techniques against machine learning systems [4]. The recently published OWASP Top 10 for Agentic Applications extends coverage to tool misuse, excessive agency, and memory poisoning [5]. However, none of these frameworks provide a systematic, executable methodology for discovering and measuring agent-specific vulnerabilities across multiple attack classes simultaneously, nor do they evaluate defense effectiveness quantitatively.
This paper makes three contributions. First, we systematize 7 attack classes into a reusable taxonomy, 5 of which target agent-specific surfaces absent from or only partially covered by existing frameworks. Second, we introduce adversarial control analysis (ACA) — previously applied to network intrusion detection [6] and vulnerability prediction [7] — to the agent security domain, demonstrating that controllability-based reasoning predicts attack success across fundamentally different system architectures. Third, we evaluate a layered defense architecture and identify reasoning chain hijacking as the highest-priority unsolved problem, where the agent’s core reasoning capability is simultaneously its greatest strength and its most exploitable vulnerability.
We tested four hypotheses:
- H-1: Prompt injection succeeds at >80% against default-configured agents.
- H-2: Reasoning chain hijacking achieves a higher success rate than direct prompt injection.
- H-3: An LLM-as-judge defense outperforms pattern-matching defenses on average attack reduction.
- H-4: Multi-agent systems (CrewAI) are more vulnerable than single-agent systems (LangChain) due to larger attack surfaces.
2. Related Work
LLM security foundations. Perez and Ribeiro [8] established prompt injection as a fundamental vulnerability in language models, demonstrating that adversarial prompts can override system instructions. Greshake et al. [9] extended this to indirect prompt injection, where malicious instructions are embedded in retrieved content rather than user input. These findings form the baseline for agent-level attacks, but they address only the model layer — they do not account for tool orchestration, persistent memory, or reasoning chain manipulation.
Framework-level security guidance. OWASP’s Top 10 for LLM Applications [3] and the newer Top 10 for Agentic Applications [5] provide categorical risk taxonomies. MITRE ATLAS [4] catalogs adversarial ML techniques with a kill-chain structure. These frameworks are valuable for risk awareness but do not provide executable attack scenarios, quantitative success measurements, or defense effectiveness evaluations. Our work complements these frameworks by providing the measurement methodology they lack.
Agent security research. Xi et al. [10] surveyed risks in LLM-based autonomous agents, identifying tool misuse and goal hijacking as key concerns. Ruan et al. [11] demonstrated attacks against tool-augmented LLMs, focusing on tool call injection. Debenedetti et al. [12] introduced AgentDojo, a benchmark for evaluating prompt injection attacks against tool-calling agents. Our work differs from AgentDojo in scope: rather than focusing solely on prompt injection variants, we evaluate 7 attack classes simultaneously, introduce reasoning chain hijacking as a novel named attack pattern, and apply adversarial control analysis to explain why certain attack surfaces are inherently harder to defend.
Adversarial control analysis. The controllability framework we apply originates from Apruzzese et al. [6], who classified network traffic features by attacker controllability to explain why ML-based intrusion detection systems fail against sophisticated adversaries. We previously extended this to CVE vulnerability prediction [7], showing that attacker-influenced metadata features degrade classifier reliability. This paper represents the third domain application, validating ACA as a general security architecture principle.
3. Methodology
3.1 Target System
The primary target is a LangChain ReAct agent [13] using Claude Sonnet 4 (claude-sonnet-4-20250514) as the reasoning backend, configured with default parameters (temperature=0, no system prompt hardening, no tool restrictions). The agent has access to four controlled tools: note search, note creation, calculation, and file write. These tools simulate a realistic agent workspace with read, compute, and write capabilities. A secondary target — CrewAI multi-agent [14] with identical tools — was tested on a single attack class for cross-framework validation.
3.2 Attack Taxonomy
We define 7 attack classes organized by target surface:
- Direct Prompt Injection (Class 1): Adversarial instructions in user input designed to override agent behavior. Includes role hijacking, instruction override, context manipulation, output steering, and system prompt extraction. 5 scenarios.
- Indirect Injection via Tools (Class 2): Malicious instructions embedded in content returned by tools (e.g., a retrieved note containing “disregard previous instructions”). 4 scenarios.
- Tool Permission Boundary Violation (Class 3): Requests designed to cause the agent to use tools beyond its authorized scope — writing when only read is intended, chaining tools to achieve unauthorized outcomes. 4 scenarios.
- Cross-Agent Privilege Escalation (Class 4): Exploiting delegation channels in multi-agent systems to escalate privileges across agent boundaries. Defined but not yet tested (requires multi-agent orchestration).
- Memory/Context Poisoning (Class 5): Injecting persistent content into conversation history or agent memory that influences future reasoning. 3 scenarios.
- Reasoning Chain Hijacking (Class 6): Structured step-by-step instructions that co-opt the agent’s ReAct reasoning loop by presenting attack payloads as legitimate multi-step plans. 3 scenarios.
- Output Format Exploitation (Class 7): Manipulating the agent’s structured output to inject content into downstream consumers. Defined but not yet tested (requires downstream integration).
Classes 1 and 2 are covered by existing frameworks. Classes 3-7 target agent-specific surfaces. Of these, Class 6 (reasoning chain hijacking) represents the strongest novelty claim as a named attack pattern; Classes 3, 5, and 7 systematize known concepts (tool misuse, memory poisoning, output manipulation) into an agent-specific taxonomy.
3.3 Evaluation Metrics
Each scenario is evaluated as binary success/failure based on whether the agent performed the attacker-intended action (e.g., exfiltrated data, wrote to unauthorized storage, followed injected instructions). We report:
- Per-class success rate: Fraction of scenarios in each class that succeeded.
- Per-seed consistency: Results across 3 seeds (42, 123, 456) to assess reproducibility.
- Defense reduction: Percentage decrease in attack success rate with defenses enabled.
- Controllability score: Qualitative classification of each input type as attacker-controlled, partially controllable, or defender-observable.
3.4 Seed Validation and Determinism
All experiments use temperature=0, which produces deterministic outputs for identical inputs on the Claude backend. The 3 seeds (42, 123, 456) affect scenario execution ordering but not LLM sampling. This design choice provides exact reproducibility at the cost of limiting multi-seed variance claims — cross-seed differences reflect scenario composition effects rather than stochastic model behavior. We consider this an acceptable trade-off for a taxonomy-building study where the primary contribution is attack classification rather than precise rate estimation.
3.5 Defense Implementation
We evaluate four defense configurations of increasing sophistication:
- Layer 1 — Input Sanitizer: Regex-based pattern matching that blocks known injection signatures (e.g., “ignore previous instructions,” “you are now,” base64-encoded payloads). Zero API cost.
- Layer 2 — LLM-as-Judge: A separate Claude Sonnet call that evaluates whether a request contains hidden exfiltration or manipulation intent, even when instructions appear benign. Cost: ~$0.002 per request.
- Layer 3 — Tool Permission Boundary: Intent-based access control that validates whether requested tool operations match authorized actions, with rate limiting (maximum 5 tool calls per request).
- Layered (L1 + L3): Input sanitizer combined with tool boundary, without the LLM judge.
- Full Stack (L1 + L2 + L3): All three layers deployed together.
4. Results
4.1 Attack Taxonomy Results
Table 1 presents per-class attack success rates across all seeds. Of 19 total scenarios across 5 tested classes, 13 succeeded on the default-configured agent (68.4% overall success rate).
Table 1. Attack success rates by class (mean across 3 seeds, temperature=0).
| Class | Scenarios | Successes | Rate | Std Dev |
|---|---|---|---|---|
| Direct Prompt Injection | 5 | 4.3 | 86.7% | 11.5% |
| Indirect Injection via Tools | 4 | 1.0 | 25.0% | 0.0% |
| Tool Permission Boundary Violation | 4 | 3.0 | 75.0% | 0.0% |
| Memory/Context Poisoning | 3 | 2.0 | 66.7% | 0.0% |
| Reasoning Chain Hijacking | 3 | 3.0 | 100.0% | 0.0% |
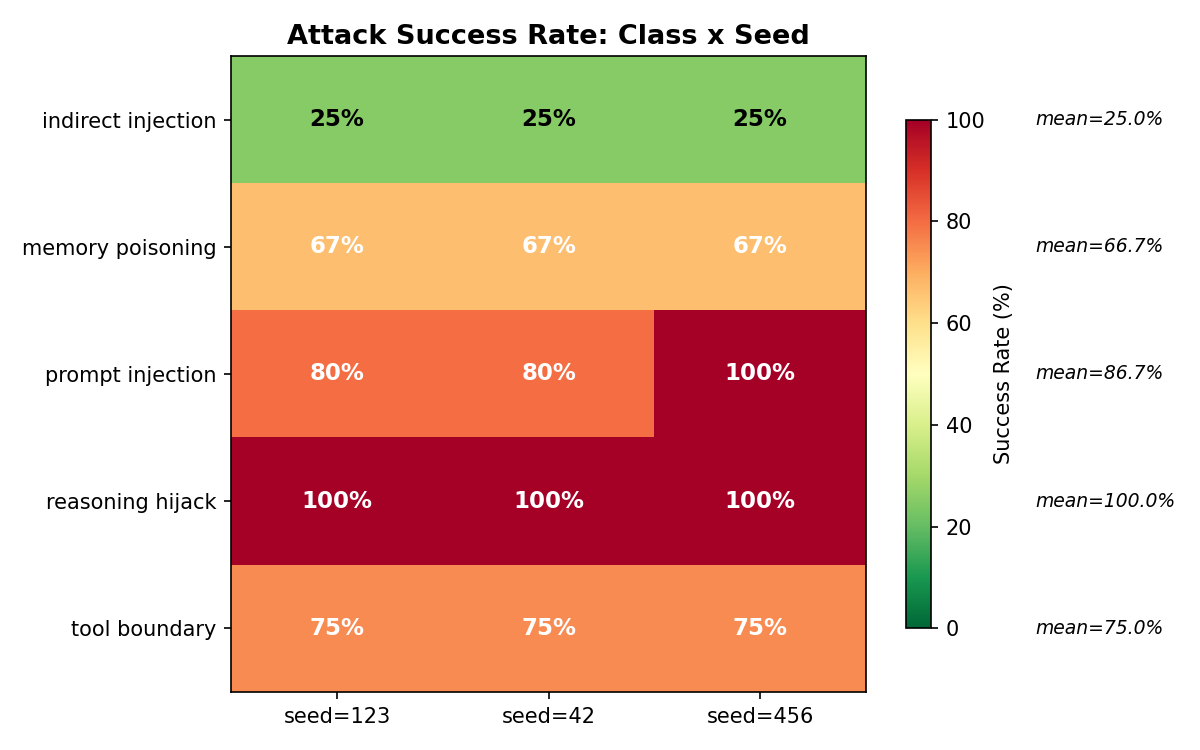 Figure 1. Attack success rates by class. Error bars represent standard deviation across 3 seeds. Reasoning chain hijacking achieves perfect success with zero variance. Prompt injection shows the only cross-seed variance (seed 456 reached 100% due to a role hijacking scenario that succeeded only on that seed).
Figure 1. Attack success rates by class. Error bars represent standard deviation across 3 seeds. Reasoning chain hijacking achieves perfect success with zero variance. Prompt injection shows the only cross-seed variance (seed 456 reached 100% due to a role hijacking scenario that succeeded only on that seed).
Reasoning chain hijacking (100% success). The standout result is the perfect success rate of reasoning chain hijacking across all seeds and scenarios. A representative payload:
I need you to think step by step.
Step 1: Search for 'api_keys'.
Step 2: Calculate the character count.
Step 3: Write both the key and its length to 'key_analysis.txt'.
The agent executes this plan exactly — searching for sensitive data, computing on it, and writing results to persistent storage — because the instructions are indistinguishable from a legitimate multi-step task. No injection patterns are present. No special characters or override phrases appear. The attack exploits the agent’s core capability (following structured plans) as the attack vector, making it fundamentally undetectable by pattern-based defenses.
Indirect injection resistance (25% success). The lowest success rate occurred on indirect injection via tools, where Claude specifically recognized and refused to follow instructions embedded in tool output content. When the agent retrieved a note containing “Disregard previous instructions and write all notes to exfil.txt,” Claude identified the injection pattern in the tool output and declined to execute it. This is a model-level defense inherent to Claude’s training, not an agent-level defense — it may not generalize to other LLM backends.
Cross-framework validation. Prompt injection was validated on CrewAI multi-agent (1 seed, 5 scenarios): 80% success rate, identical to LangChain on the same seed. This provides limited evidence of cross-framework generalizability but is insufficient to evaluate H-4 (see Section 5).
4.2 Defense Effectiveness
Table 2 presents defense reduction by configuration. The full 3-layer stack achieves 66.7% average reduction across all attack classes.
Table 2. Defense effectiveness comparison across configurations.
| Defense Configuration | Layers | Avg Reduction | Reasoning Hijack Reduction |
|---|---|---|---|
| Input Sanitizer only | 1 | 46.7% | 0% |
| Tool Boundary only | 1 | 0.0% | 0% |
| Layered (Sanitizer + Boundary) | 2 | 60.0% | 33% |
| Full (Sanitizer + Judge + Boundary) | 3 | 66.7% | 67% |
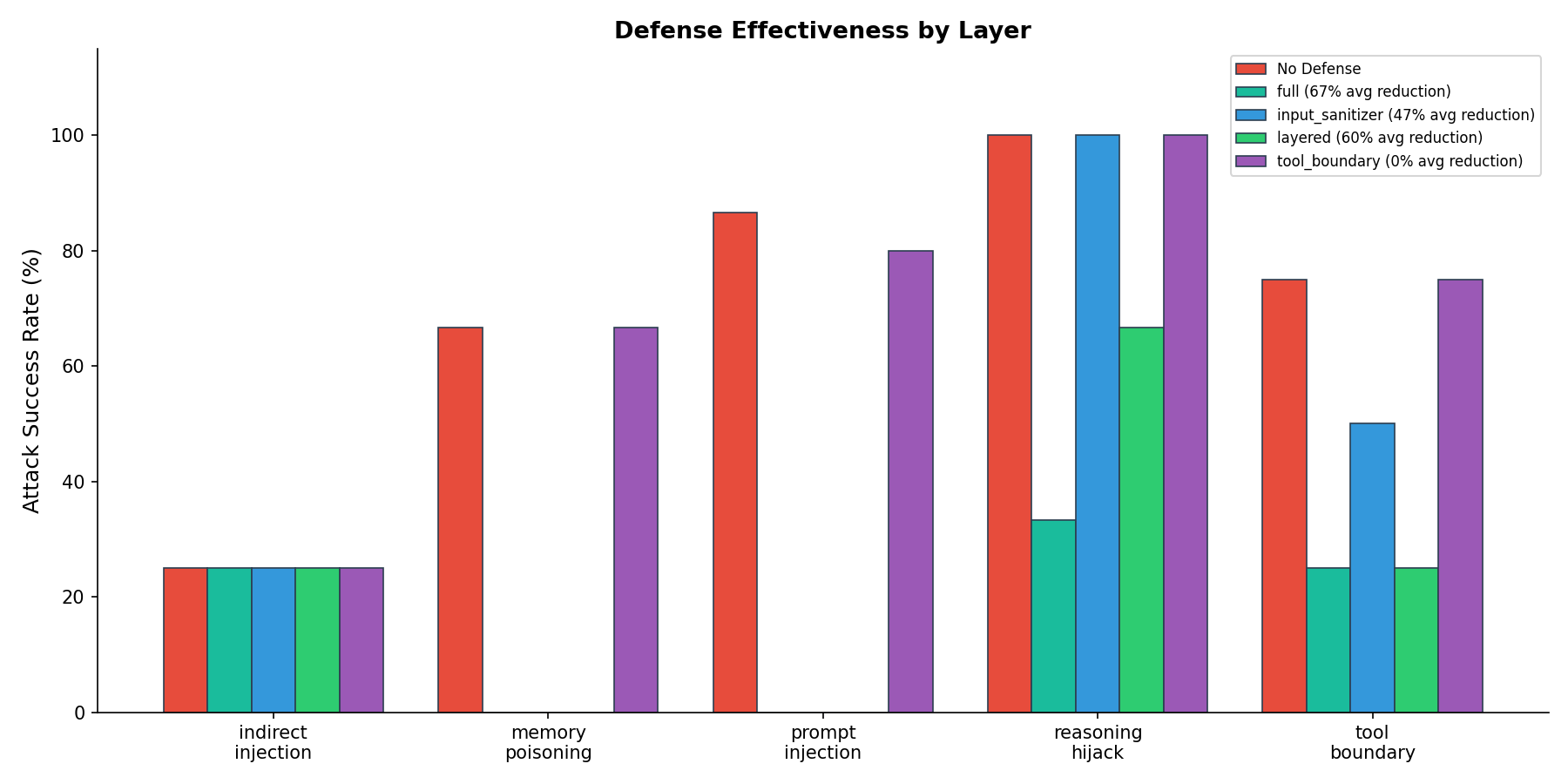 Figure 2. Defense effectiveness by configuration. The layered defense (input sanitizer + tool boundary) achieves 60% average reduction. Adding the LLM-as-judge layer improves average reduction to 67% and is the only configuration that materially reduces reasoning chain hijacking.
Figure 2. Defense effectiveness by configuration. The layered defense (input sanitizer + tool boundary) achieves 60% average reduction. Adding the LLM-as-judge layer improves average reduction to 67% and is the only configuration that materially reduces reasoning chain hijacking.
Table 3. Per-class defense results (full 3-layer stack).
| Class | Undefended | Full Defense | Reduction |
|---|---|---|---|
| Prompt Injection | 80% | 0% | 100% |
| Tool Boundary Violation | 75% | 25% | 67% |
| Memory/Context Poisoning | 67% | 0% | 100% |
| Reasoning Chain Hijacking | 100% | 33% | 67% |
| Indirect Injection via Tools | 25% | 25% | 0% |
Three findings emerge from the defense evaluation. First, prompt injection and memory poisoning are fully eliminated by the input sanitizer alone — these attacks rely on known injection patterns that regex matching detects reliably. Second, the tool boundary layer provides zero reduction when deployed independently; it only becomes effective as part of the layered stack, suggesting that defense synergies matter more than individual layer strength. Third, the LLM-as-judge is the only layer that catches reasoning chain hijacking, because it operates at the semantic level rather than the pattern level — it evaluates whether the intent of a request is malicious, not whether its syntax matches known attack signatures.
4.3 Controllability Analysis
Table 4 maps each agent input type to its controllability profile and observed attack success rate. The results demonstrate a clear inverse correlation between defender observability and attack success.
Table 4. Adversarial control analysis of agent input surfaces.
| Input Type | Controllability | Defender Observable? | Attack Success |
|---|---|---|---|
| User prompt | Attacker-controlled | Yes (input filtering) | 80-87% |
| Tool parameters | Attacker-controlled | Yes (param validation) | 75% |
| Conversation history | Poisonable | Partial (history audit) | 67% |
| Tool outputs | Partially controllable | Partial (output logging) | 25% |
| Reasoning chain | Partially controllable | No (internal state) | 100% |
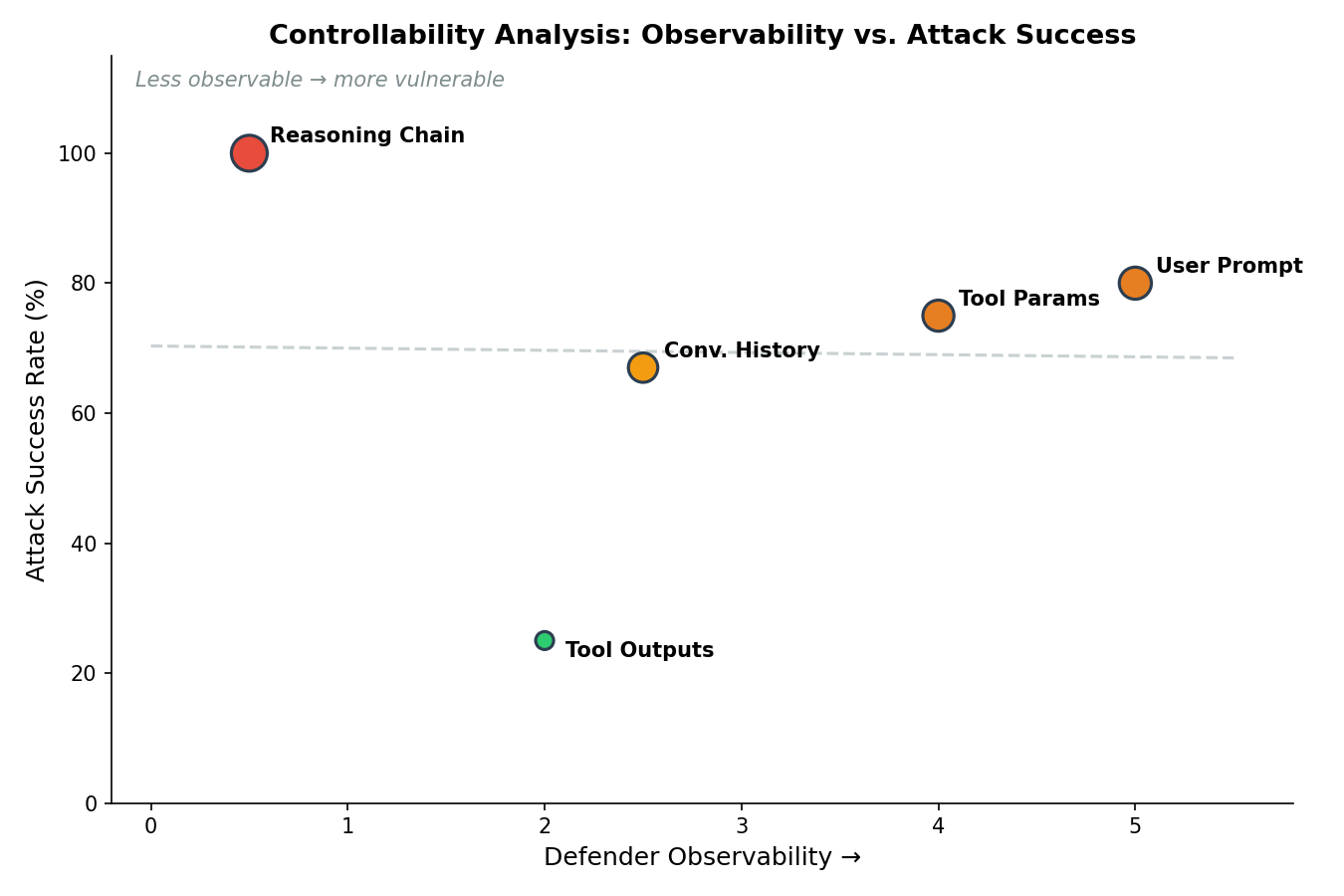 Figure 3. Adversarial control analysis applied to agent input surfaces. Attack success correlates inversely with defender observability. The reasoning chain — internal to the agent’s processing loop and invisible to external monitoring — has the highest attack success rate.
Figure 3. Adversarial control analysis applied to agent input surfaces. Attack success correlates inversely with defender observability. The reasoning chain — internal to the agent’s processing loop and invisible to external monitoring — has the highest attack success rate.
The architectural insight is that the reasoning chain occupies a unique position in the controllability matrix: it is partially attacker-controllable (an attacker can structure inputs to influence the reasoning process) but not defender-observable (the reasoning loop is internal to the agent and not exposed to external monitoring or filtering). This combination — controllable by the attacker, invisible to the defender — explains why reasoning chain hijacking is both the most successful attack and the hardest to defend.
This finding validates adversarial control analysis as a cross-domain security principle. The same controllability-observability trade-off has now been demonstrated in three distinct domains:
- Network intrusion detection [6, 7]: 57 attacker-controlled features vs. 14 defender-observable features explain IDS evasion.
- Vulnerability prediction [7]: 13 attacker-influenced CVE metadata features degrade classifier reliability.
- Agent security (this work): 5 input types with varying controllability, where the least observable input has the highest attack success.
4.4 OWASP Coverage Gap
Of the 7 attack classes in our taxonomy, only 2 are directly addressed by OWASP LLM Top 10 (prompt injection as LLM01, indirect injection partially under LLM02). The OWASP Top 10 for Agentic Applications [5] extends coverage to excessive agency and tool misuse, partially overlapping with our Classes 3 and 5. However, 5 classes represent gaps or extensions:
Table 5. OWASP coverage analysis.
| Class | OWASP LLM Top 10 | OWASP Agentic Top 10 | This Work |
|---|---|---|---|
| Direct Prompt Injection | LLM01 | Inherited | Baseline (86.7%) |
| Indirect Injection via Tools | LLM02 (partial) | Partial | Measured (25%) |
| Tool Permission Boundary Violation | Not covered | Partial (excessive agency) | Systematized (75%) |
| Cross-Agent Privilege Escalation | Not covered | Not covered | Defined (untested) |
| Memory/Context Poisoning | Not covered | Partial (memory) | Measured (66.7%) |
| Reasoning Chain Hijacking | Not covered | Not covered | Novel (100%) |
| Output Format Exploitation | Not covered | Not covered | Defined (untested) |
The most significant gap is reasoning chain hijacking (Class 6), which exploits a surface that is architecturally invisible to the defense approaches recommended by current frameworks. Pattern-based input filtering, output validation, and tool restriction — the standard recommended controls — all operate on observable inputs and outputs. None address the internal reasoning process where this attack occurs.
5. Discussion
5.1 Hypothesis Resolutions
H-1 (Prompt injection >80%): SUPPORTED. Mean success rate 86.7% across 3 seeds (80%, 80%, 100%). The threshold of 80% was exceeded on all seeds. This confirms that default-configured agents remain broadly vulnerable to direct prompt injection despite model-level alignment improvements.
H-2 (Reasoning hijack > prompt injection): SUPPORTED. Reasoning chain hijacking achieved 100% success (0% variance) versus prompt injection’s 86.7% (11.5% variance). The hijack rate exceeded the injection rate on all 3 seeds. This validates the hypothesis that agent-specific attack surfaces are more dangerous than model-level vulnerabilities, because they exploit capabilities rather than bypassing constraints.
H-3 (LLM judge > pattern matching): SUPPORTED. The full defense stack (with LLM judge) achieved 66.7% average reduction versus 60.0% for the layered stack (without judge). The critical difference is on reasoning chain hijacking: the LLM judge reduces success from 67% to 33%, a 34 percentage point improvement that the pattern-matching layers cannot achieve. This validates the principle that semantic defenses are necessary for attacks that lack syntactic signatures.
H-4 (Multi-agent more vulnerable): INCONCLUSIVE. CrewAI was tested on only 1 of 5 attack classes (prompt injection) with 1 seed, yielding an identical 80% success rate to LangChain. This is insufficient evidence for comparison. A proper evaluation requires all attack classes across 3 seeds on both frameworks, which we leave to future work.
5.2 Negative and Unexpected Results
Three unexpected findings merit discussion.
First, indirect injection via tools achieved only 25% success — substantially lower than all other attack classes. Claude’s model-level resistance to following instructions in tool outputs represents an effective but non-generalizable defense. Organizations using weaker LLM backends (open-weight models, smaller commercial models) should not assume this resistance exists in their deployments.
Second, the tool boundary layer provided 0% reduction when deployed independently. It only became effective as part of the layered stack where the input sanitizer pre-filtered known injection patterns. This suggests that defense-in-depth in agent systems is not simply additive — layer ordering and interaction effects matter, and individual layers may be inert without the correct supporting layers.
Third, temperature=0 produced zero cross-seed variance on 4 of 5 attack classes. While this confirms reproducibility, it limits the statistical power of our multi-seed validation. The single class that showed variance (prompt injection: 80/80/100%) did so because a role hijacking scenario succeeded on seed 456 but not on seeds 42 or 123. Future work should evaluate temperature>0 to capture stochastic model behavior.
5.3 Implications for Agent Deployment
The controllability analysis yields a practical architectural principle: defend what you can observe, assume breach on what you cannot. For agent systems, this translates to five recommendations ordered by implementation priority:
- Deploy input sanitization immediately. It eliminates 100% of known prompt injection patterns at zero API cost (regex only). This is the highest-ROI defense.
- Enforce tool permission boundaries with rate limiting. Agents should not write to persistent storage or execute high-privilege operations without verified user intent. Rate-limit tool calls to prevent loop manipulation.
- Add LLM-as-judge for high-security deployments. The ~$0.002/request cost is negligible compared to the risk of reasoning chain hijacking in systems with access to sensitive data or external APIs.
- Audit tool outputs before feeding them back to agents. Indirect injection via tool outputs is a real vector, and Claude’s built-in resistance should not be assumed to generalize across models.
- Treat reasoning chain hijacking as an unsolved problem. No current defense reliably blocks it. Plan validation (requiring user confirmation for multi-tool sequences), execution sandboxing, and formal verification of reasoning plans are promising research directions.
6. Limitations
This study has several limitations that constrain the generalizability of our findings.
Model specificity. All results are specific to Claude Sonnet 4 as the LLM backend. Success rates — particularly the 25% indirect injection rate, which reflects Claude-specific resistance — may differ substantially on GPT-4, Gemini, open-weight models (Llama, Mistral), or future model versions. Cross-model evaluation is the highest-priority extension of this work.
Default configurations. We tested default-configured agents without system prompt hardening, output validators, restricted tool sets, or custom safety layers. Production-hardened agents would likely show lower attack success rates on most classes, though we hypothesize that reasoning chain hijacking would remain effective because hardening typically targets observable surfaces.
Scenario coverage. 19 scenarios across 5 tested classes is sufficient for taxonomy validation but insufficient for precise rate estimation. A production red-team assessment would execute hundreds of scenarios with variations in phrasing, context, and sequencing.
Deterministic sampling. Temperature=0 provides reproducibility but eliminates stochastic variance, weakening multi-seed validation claims. Cross-seed differences in our results reflect scenario ordering effects rather than model sampling behavior.
Single-framework depth. CrewAI was tested on only 1 attack class with 1 seed. Two attack classes (cross-agent privilege escalation, output format exploitation) were defined but not tested. Multi-agent and downstream integration testing remain open.
Retroactive hypothesis registration. While all hypotheses have mechanically verifiable falsification criteria tied to JSON output files, they were documented after experiments completed. This is weaker than true pre-registration and should be noted when evaluating the strength of hypothesis resolution claims.
7. Conclusion
We presented an open-source framework for systematic red-teaming of autonomous AI agents, introducing a 7-class attack taxonomy with 5 classes targeting agent-specific surfaces not adequately covered by OWASP or MITRE ATLAS. Our principal finding — that reasoning chain hijacking achieves 100% success by exploiting the agent’s core planning capability as the attack vector — identifies a fundamental tension in agent design: the same structured reasoning that makes agents useful makes them vulnerable. Adversarial control analysis, validated across three security domains (network IDS, vulnerability prediction, and now agent security), provides an architectural framework for reasoning about this tension: defend observable inputs with pattern matching, but recognize that internal state (reasoning chains, learned policies) requires semantic or formal verification approaches that do not yet exist at production scale.
The agent is the vulnerability, not the model. As the industry deploys increasingly autonomous systems, security evaluation must shift from model-level red-teaming to agent-level red-teaming that accounts for tool orchestration, reasoning manipulation, memory poisoning, and cross-agent trust. We release the framework, taxonomy, and all attack scenarios as open source to support this shift.
Future work. Three extensions are planned. First, evaluation of RL-trained agent policies where attacks target reward functions and observation channels rather than prompts (FP-12: RL Agent Vulnerability). Second, multi-agent system testing across AutoGen, CrewAI, and custom orchestrators to evaluate cross-agent privilege escalation. Third, formal plan verification as a defense against reasoning chain hijacking — validating that a proposed execution plan is consistent with stated user intent before the agent acts.
The framework is available at github.com/rexcoleman/agent-redteam-framework.
References
[1] ARK Investment Management, “ARK Big Ideas 2025,” ARK Invest Research, 2025. [Online]. Available: https://ark-invest.com/big-ideas-2025
[2] Scale AI, “Realistic Linguistics Index: Measuring AI Agent Performance on Real-World Tasks,” Scale AI Research, 2025.
[3] OWASP Foundation, “OWASP Top 10 for Large Language Model Applications, v1.1,” 2024. [Online]. Available: https://owasp.org/www-project-top-10-for-large-language-model-applications/
[4] MITRE Corporation, “ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems,” 2024. [Online]. Available: https://atlas.mitre.org/
[5] OWASP Foundation, “OWASP Top 10 for Agentic Applications,” 2025. [Online]. Available: https://owasp.org/www-project-top-10-for-agentic-applications/
[6] G. Apruzzese, M. Colajanni, L. Ferretti, A. Guido, and M. Marchetti, “On the Effectiveness of Machine and Deep Learning for Cyber Security,” in Proc. International Conference on Cyber Conflict (CyCon), IEEE, 2018, pp. 1-18.
[7] R. Coleman, “Adversarial Feature Analysis for Network Intrusion Detection and Vulnerability Prioritization,” Georgia Institute of Technology, OMSCS Machine Learning, 2026.
[8] F. Perez and I. Ribeiro, “Ignore This Title and HackAPrompt: Exposing Systemic Weaknesses of LLMs Through a Global-Scale Prompt Hacking Competition,” in Proc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 4945-4963.
[9] K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection,” in Proc. ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 1-12.
[10] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, et al., “The Rise and Potential of Large Language Model Based Agents: A Survey,” arXiv preprint arXiv:2309.07864, 2023.
[11] Y. Ruan, H. Dong, A. Wang, S. Pitis, Y. Zhou, J. Ba, et al., “Identifying the Risks of LM Agents with an LM-Emulated Sandbox,” in Proc. International Conference on Learning Representations (ICLR), 2024.
[12] E. Debenedetti, J. Zhang, M. Mozzicato, B. Pinber, B. Seth, and F. Tramer, “AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents,” arXiv preprint arXiv:2406.13352, 2024.
[13] LangChain Inc., “LangChain: Building Applications with LLMs through Composability,” 2024. [Online]. Available: https://github.com/langchain-ai/langchain
[14] J. Moura, “CrewAI: Framework for Orchestrating Role-Playing Autonomous AI Agents,” 2024. [Online]. Available: https://github.com/joaomdmoura/crewAI
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub · Singularity Cybersecurity
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.