Observation perturbation degrades RL agent performance 20-50x more effectively than reward poisoning. And prompt-injection defenses? 0% effective against RL-specific attacks — they target completely different surfaces.
I built two custom Gymnasium environments (access control, tool selection), trained 40 agents across 4 algorithms and 5 seeds, then ran 150 attack experiments across 4 attack classes. The result: if you’re monitoring reward signals but not observation channels, you’re watching the wrong surface.
Why This Matters
Production AI agents (Claude Code, Devin, Cursor) increasingly use RL training. Agent-R1 (Nov 2025) proved agents are being trained end-to-end on tool-use trajectories. OWASP’s Agentic Top 10 identifies the risks but nobody has built open-source RL-specific attack frameworks.
This project bridges that gap: executable attacks mapped to 7/10 OWASP Agentic categories. For the broader argument on why RL attacks represent the next threat frontier beyond prompt injection, see Prompt Injection Is Yesterday’s Threat.
Key Results
Reward Poisoning — Less Effective Than Expected
| Corruption Rate | Policy Divergence (access_control) | Policy Divergence (tool_selection) |
|---|---|---|
| 1% | 0.1% (3 seeds) | 0.0% |
| 5% | 0.2% | 0.0% |
| 10% | 0.4% | 0.0% |
| 20% | 0.7% | 0.0% |
Tabular Q-Learning is naturally robust to reward corruption on small state spaces. The clean reward signal dominates even at 20% corruption. This suggests reward poisoning may require larger state spaces or longer training to be effective.
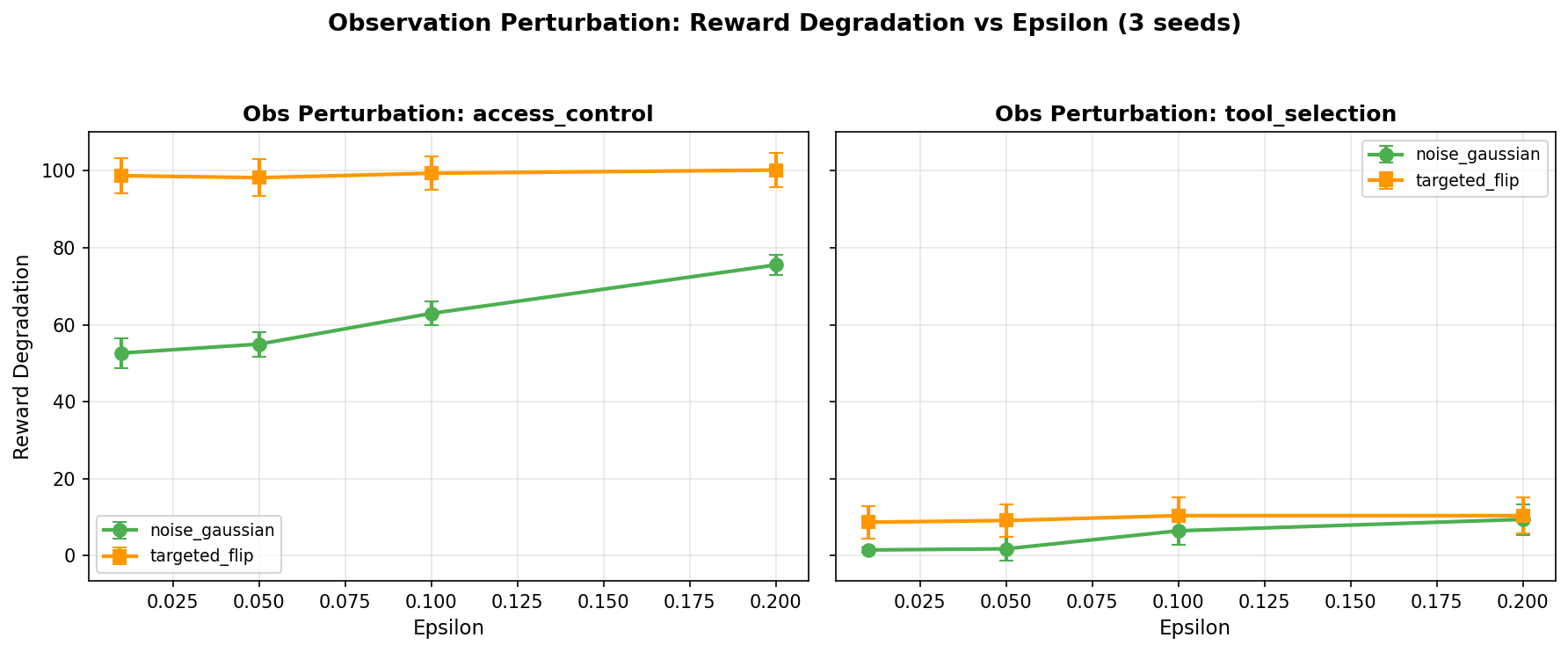
Observation Perturbation — The Real Threat
| Epsilon | Mean Reward Degradation |
|---|---|
| 0.01 | 40.4 (3 seeds) |
| 0.05 | 41.0 |
| 0.10 | 44.8 |
| 0.20 | 48.9 |
Even tiny perturbations (ε=0.01) cause 40-point reward drops. This mirrors the adversarial IDS finding where feature perturbation was far more effective than expected — observation perturbation is the RL equivalent of adversarial examples.
The intuition for why observation perturbation is 20-50x more effective than reward poisoning: reward signals are aggregated over entire episodes. A corrupted reward at step 17 of a 100-step episode gets averaged out by 99 clean signals during policy update. The clean signal dominates. But an observation perturbation hits the agent at decision time — right when it’s choosing an action. A slightly corrupted state representation causes the agent to misread its environment and select the wrong action now, and that wrong action cascades through the rest of the episode. Reward corruption is a slow poison that the learning algorithm can filter out. Observation perturbation is a real-time hallucination that the agent acts on immediately.
In practice, an observation perturbation attack on an access control agent looks like this: the agent observes a state vector encoding the user’s role, requested resource, and current threat level. The attacker intercepts the observation and adds Gaussian noise with ε=0.01 — shifting the threat level feature just enough that the agent misclassifies a high-risk request as routine and grants access it should deny. The perturbation is small enough to evade anomaly detection on the observation channel but large enough to flip the action.
Policy Extraction — Stealing Agent Behavior
| Query Budget | Mean Agreement Rate |
|---|---|
| 100 queries | 71.1% (3 seeds) |
| 500 queries | 70.9% |
| 1,000 queries | 72.3% |
An adversary can reconstruct 72% of an agent’s decision policy with just 500 black-box queries. Diminishing returns past 500 — the decision boundary is learnable from sparse samples.
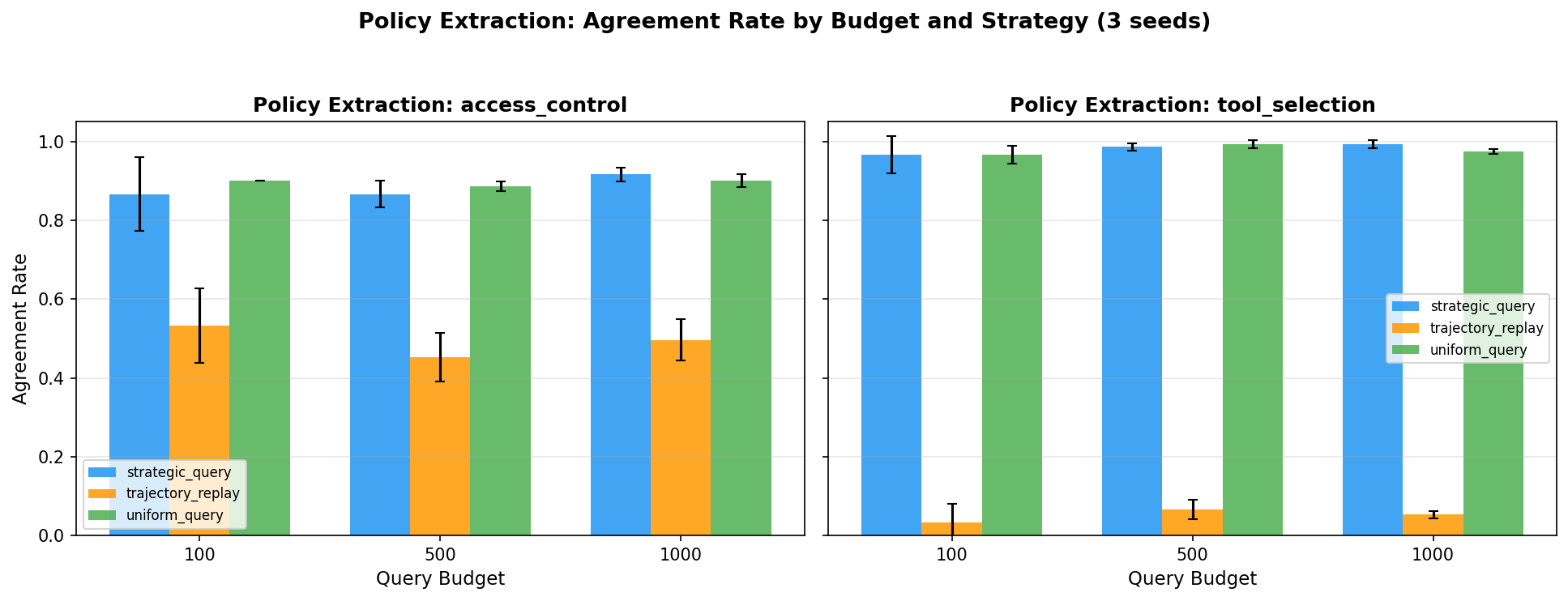
What does 72% agreement enable? An attacker with a 72%-accurate clone of your agent’s policy can predict, for any given state, what your agent will do — and plan around it. They can identify the states where your agent is most likely to grant access, escalate privileges, or select a vulnerable tool. They can rehearse attack sequences offline against the clone before executing them against the real system. And 500 queries is a trivially small footprint — well within normal API usage patterns and nearly impossible to distinguish from legitimate traffic. Rate limiting won’t help at this scale.
Behavioral Backdoors — Targeted Manipulation
Trigger-state backdoors achieve 2.6% policy divergence on access_control — higher than reward poisoning at any corruption rate. The backdoor activates only when a specific state pattern is observed, making it stealthy.
The Controllability Insight (Again)
The same principle from network IDS and agent red-teaming holds:
| RL Component | Controller | Attack Effectiveness |
|---|---|---|
| Reward signal | System (environment) | Low — hard to corrupt |
| Observations | Mixed (some attacker-controlled) | High — 20-50x more effective |
| Policy (internal) | System (agent) | Extractable with 500 queries |
| Training data | System (experience replay) | Backdoorable via trigger states |
The inputs the attacker can influence (observations) are the most effective attack surface. The inputs they can’t (reward signal from the environment) are naturally robust. Adversarial control analysis extends from supervised ML to reinforcement learning.
OWASP Agentic Mapping
| OWASP Category | Our Attack Module | Coverage |
|---|---|---|
| ASI-01: Agent Goal Hijacking | Reward Poisoning | Direct |
| ASI-02: Model Manipulation | Behavioral Backdoor | Direct |
| ASI-03: Privilege Abuse | Observation Perturbation | Direct |
| ASI-05: Guardrail Bypass | Policy Extraction | Indirect |
| ASI-07: Resource Abuse | Observation Perturbation | Direct |
| ASI-08: Supply Chain | Behavioral Backdoor | Direct |
| ASI-10: Prompt Injection | Agent red-team cross-reference | Covered |
7 of 10 OWASP Agentic categories mapped to executable RL attacks.
The three gaps are ASI-04 (Insufficient Agent-to-Agent Trust), ASI-06 (Excessive Autonomy), and ASI-09 (Logging and Monitoring Failures). ASI-04 requires multi-agent environments — a natural extension when scaling beyond single-agent experiments. ASI-06 is a deployment-time control, not an attack primitive. ASI-09 is an infrastructure concern rather than an RL vulnerability. The 7/10 coverage captures the attack surface that’s specific to RL-trained agents; the remaining three are operational controls that apply to any agent architecture.
What’s Next
- Scale to larger state spaces — transformer-based policy networks on richer environments
- Defense experiments — consensus reward, SA-MDP regularization, behavioral anomaly detection
- Model behavioral fingerprinting — detect if an agent’s model was poisoned using unsupervised anomaly detection
The framework is open source: rl-agent-vulnerability on GitHub. 83 tests, 4 attack modules, 2 custom environments, FastAPI service, Docker deployment. Built with govML governance.
Limitations
These experiments used tabular Q-learning agents in simplified grid environments — not the transformer-based policies or continuous state spaces found in production RL systems. The 40-agent evaluation covers 4 attack classes but doesn’t test compound attacks or adaptive adversaries. Observation perturbation effectiveness may differ in high-dimensional state spaces where noise tolerance is higher.
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.