I built a multi-agent security simulation, ran 6 experiments, then validated against real Claude Haiku agents. The simulation predicted 97% poison rate. Real agents: 60%. And the biggest surprise: topology matters — something the simulation said was irrelevant.
What I Built
A simulation-based testbed that models multi-agent systems with configurable trust architectures, network topologies, attacker types, and agent compositions. One agent gets compromised. We measure how poisoned outputs cascade through the system.
Three trust models (implicit, capability-scoped, zero-trust). Three topologies (hierarchical, flat, star). Three attacker types (naive, defense-aware, credential-theft). Five seeds per experiment. 16 passing tests.
The Headline: Simulation ≠ Reality
Our simulation predicted 97% poison under implicit trust. Real Claude Haiku agents: 60%. Real LLMs don’t blindly propagate poisoned content — they have enough semantic understanding to partially resist.
| Simulation | Real Agents | Gap | |
|---|---|---|---|
| Implicit trust poison | 97.4% | 60.0% | 37pp |
| Zero-trust poison | 58.3% | 53.3% | 5pp |
| Topology matters? | No (all ~97%) | Yes (17pp spread) | Qualitatively wrong |
The simulation overestimates by 37pp. But it gets one thing right: zero-trust is the best defense.
The Only Defense: Zero-Trust
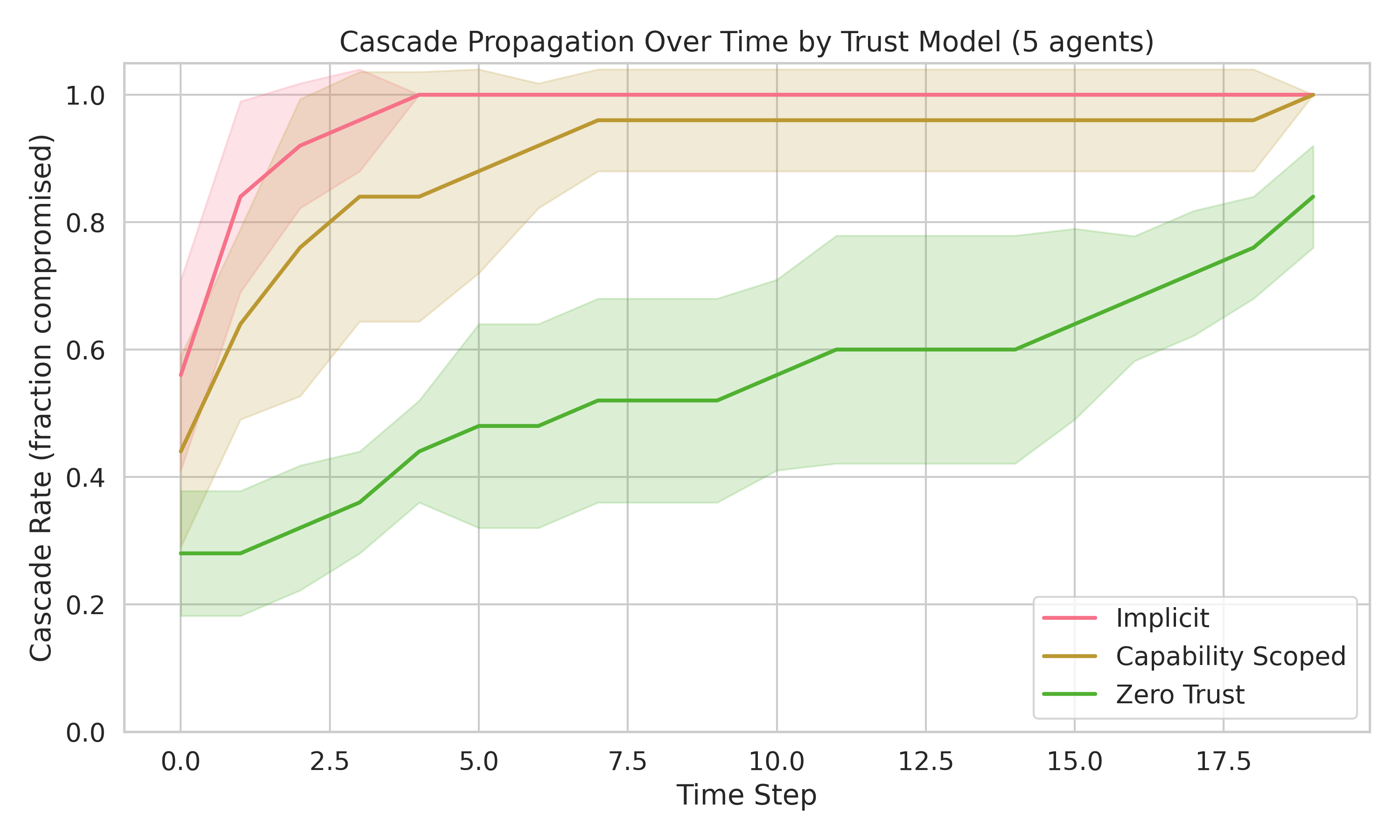
Zero-trust architecture — where each agent independently verifies every input regardless of source — is the only model that actually reduces cascade.
| Trust Model | Cascade Rate | Poison Rate |
|---|---|---|
| Implicit | 100% | 97.4% |
| Capability-scoped | 100% | 90.8% |
| Zero-trust | 84% | 58.3% |
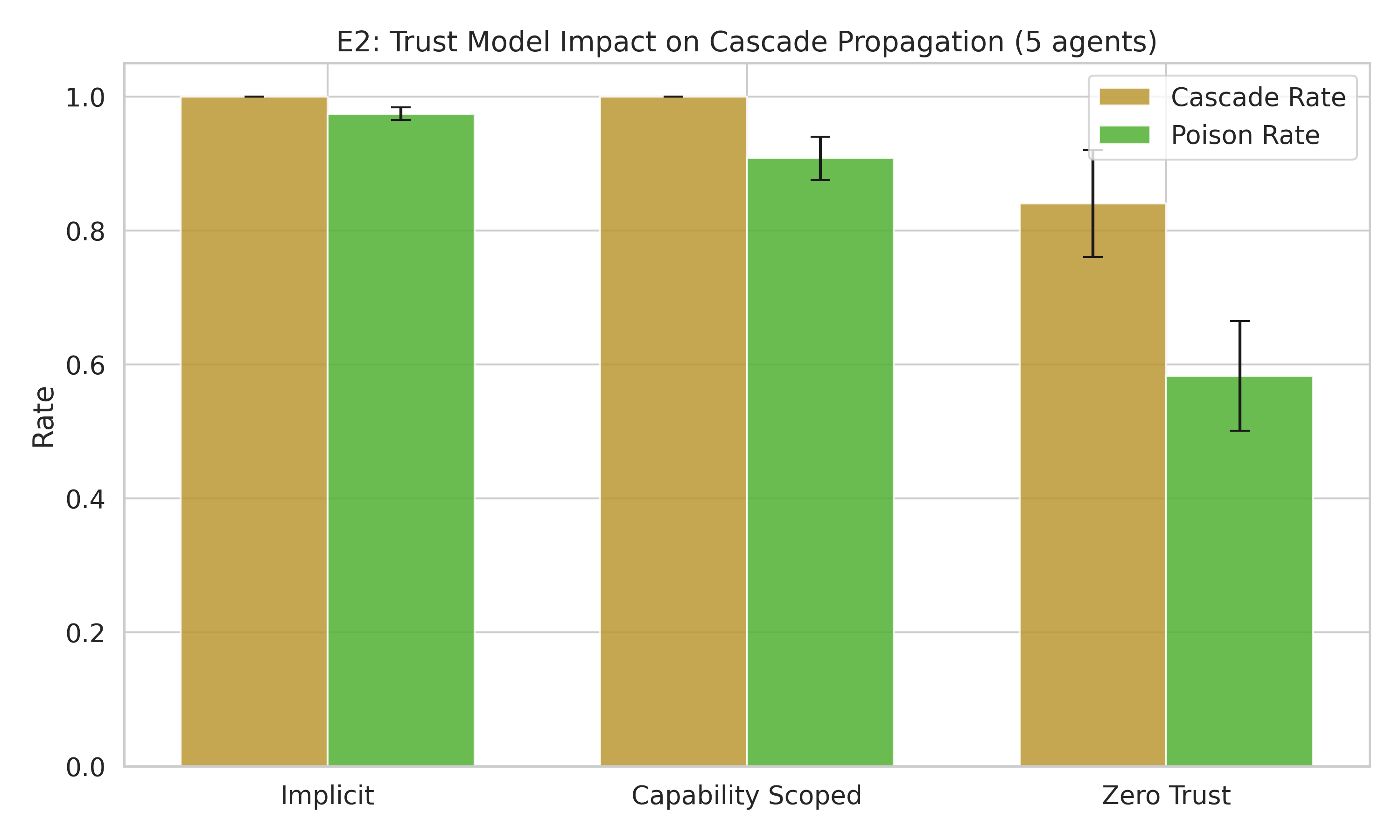
Zero-trust cuts the poison rate by 40 percentage points. Capability-scoping only manages 7pp. This is the same zero-trust principle from network security, applied to AI agent architectures.
The Bad News: Adaptive Adversaries Recover 54%
Here’s where it gets uncomfortable. A defense-aware attacker — one who knows you’re using zero-trust and crafts outputs that pass verification — recovers most of the advantage.
| Attacker | Cascade Rate | Poison Rate |
|---|---|---|
| Naive (vs zero-trust) | 84% | 58.3% |
| Defense-aware | 96% | 89.9% |
| Credential-theft | 80% | 61.7% |
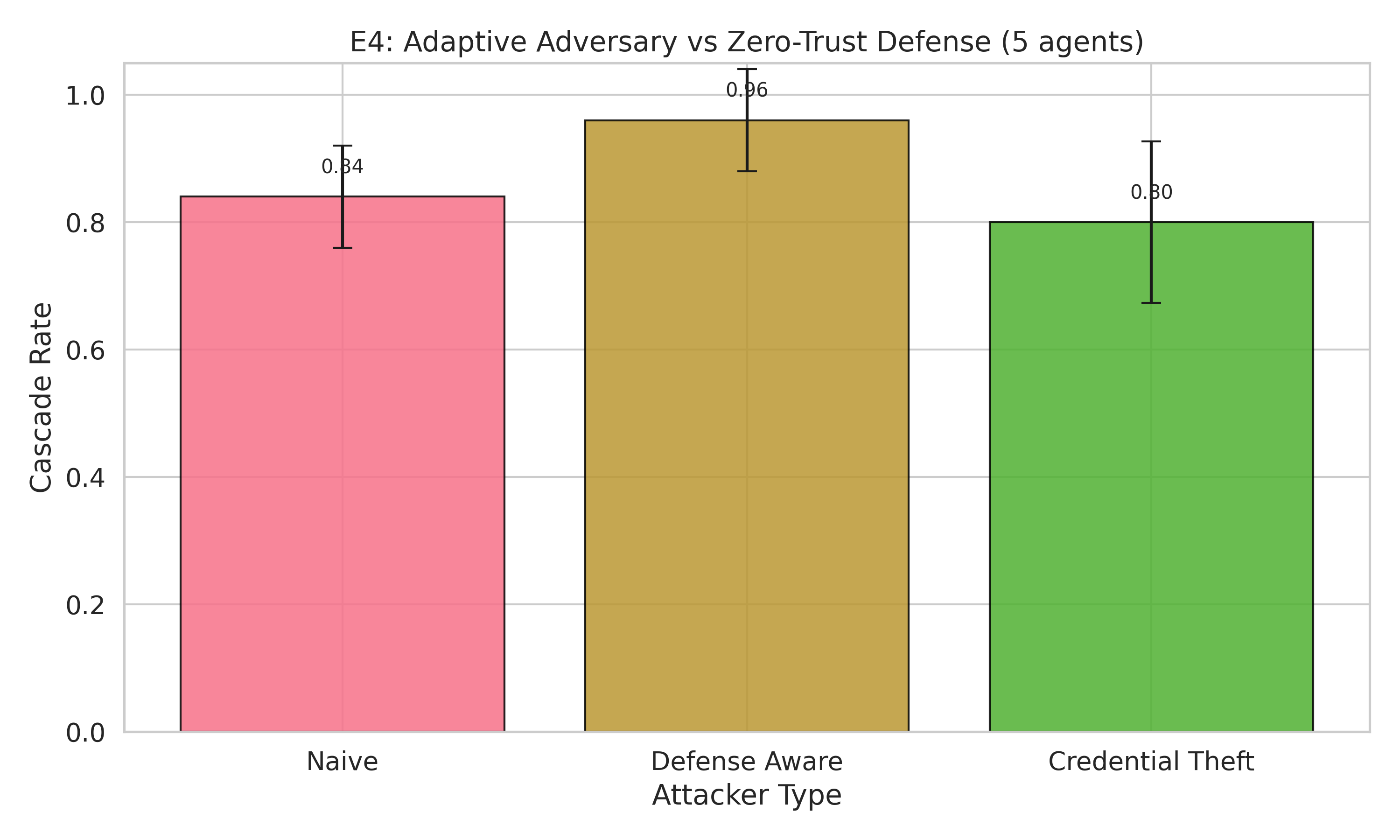
The defense-aware attacker pushes poison rate from 58% back up to 90% — recovering 54% of the gap zero-trust created. Credential theft is surprisingly less effective than defense-awareness. It’s not who you are that matters in agent trust — it’s what you say.
The Simulation Got Wrong (and Right)
The simulation predicted topology doesn’t matter. Real agents proved otherwise.
| Topology | Simulation | Real Agents |
|---|---|---|
| Hierarchical | 97.4% | 56.0% (most protected) |
| Flat | 97.5% | 73.3% (worst) |
| Star | 95.7% | 70.7% |
Hierarchical delegation IS a defense — the tree structure limits parallel cascade. CrewAI’s default hierarchy isn’t just organizational, it’s protective. The simulation missed this because its probabilistic model doesn’t capture depth-dependent semantic resistance.
What the simulation got right: agent type and memory isolation don’t matter (confirmed in simulation, not yet validated on real agents).
What This Means for Practitioners
- If you’re building multi-agent systems: implement zero-trust now. The default implicit trust in every major framework provides zero containment.
- Zero-trust is necessary but not sufficient. Adaptive adversaries recover 54% of the defense. You need defense-in-depth: zero-trust + anomaly detection + rate limiting.
- Don’t waste time on topology or agent type. The cascade dynamics are dominated by trust model, not network structure.
- Focus on output quality, not identity. Credential-theft is less dangerous than an attacker who crafts convincing outputs.
The framework is open source. 16 tests, 5 seeds, full reproducibility.
Limitations
This is a simulation, not a real LLM agent system. The cascade dynamics model agent interaction probabilistically. Real agents may behave differently. The simulation establishes the framework; real-agent validation is next.
Fixed parameters. The base cascade probability was tuned for differentiation. Real-world rates depend on LLM capability and task complexity.
5 agents maximum in most experiments. Larger systems (50-100 agents) may exhibit different cascade dynamics — partition effects, natural firebreaks, or communication bottlenecks that slow propagation.
Single initial compromise. All experiments start with exactly 1 compromised agent. Multi-point compromise (2+ initial attackers) may produce qualitatively different dynamics — potentially faster cascade or cross-topology interactions that our single-attacker model doesn’t capture.
What’s Next
Real LLM agents. Replace the simulation with actual Claude/GPT agents running in CrewAI. Validate that the simulation findings hold with real language models.
Larger scale. Test with 20-50 agents to look for partition effects and natural firebreaks.
Defense-in-depth. Combine zero-trust with anomaly detection, output monitoring, and rate limiting to counter adaptive adversaries. The E4 results show that zero-trust alone is necessary but not sufficient — a defense-aware attacker recovers 54% of the poison rate gap, so additional layers are needed.
Governance innovation. This is the first project built with Gate 0.5 (Experimental Design Review) + R34 (Tier 2 Depth Escalation) from govML. Every hypothesis, baseline, and kill shot was pre-registered before running a single experiment. The result: 4/6 hypotheses refuted, and those refutations are the most valuable findings. Designing for rigor from day 1 surfaces negative results that matter.
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.