A model poisoned through training data — one that behaves normally on 99.9% of inputs and activates a backdoor only on a specific trigger — passes every static analysis check. I built a behavioral fingerprinting system that detects these models using unsupervised anomaly detection: zero labeled backdoor examples, no model retraining, AUROC 0.62 on deliberately subtle synthetic backdoors.
Static tools like ModelScan catch serialization exploits. Behavioral fingerprinting catches what static misses — and the defender controls the probe inputs, inverting the usual attacker advantage. This is a model supply chain problem analogous to the agent skill supply chain — in both cases, third-party artifacts execute inside your system and static analysis misses behavioral threats.
The Approach: Behavioral Fingerprinting
The idea is borrowed from malware analysis. Traditional antivirus scans file signatures. Behavioral analysis runs the binary and watches what it does. Same principle, applied to ML models.
The pipeline:
- Feed the model a curated set of reference inputs (controlled by the defender)
- Extract activation patterns from intermediate layers
- Build a baseline of “normal” behavior from known-clean models
- Flag models whose activations deviate from that baseline
No labeled backdoor examples needed. No model retraining. Pure unsupervised anomaly detection.
The Experiment
I ran 150 experiments: 6 anomaly detectors crossed with 5 feature representations, each across 5 random seeds.
Detectors: Isolation Forest, One-Class SVM, GMM, Autoencoder, PCA + Mahalanobis distance, Local Outlier Factor
Representations: Raw activations, PCA, ICA, Random Projection, plus a contrastive learning (SimCLR) baseline
Data: 200 synthetic model fingerprints per seed (160 clean training, 40 test with 8 backdoored). Synthetic data is a limitation – real-model validation is next – but it lets me control the difficulty of the backdoor signal precisely.
Result 1: It Works (Modestly)
Every detector on raw features exceeds random chance (AUROC > 0.50):
| Detector | Mean AUROC | Detection Rate @ FPR=10% |
|---|---|---|
| Local Outlier Factor | 0.622 | 27.5% |
| One-Class SVM | 0.616 | 22.5% |
| Autoencoder | 0.616 | 25.0% |
| Isolation Forest | 0.605 | 27.5% |
| PCA + Mahalanobis | 0.595 | 15.0% |
| GMM | 0.589 | 25.0% |
Best single run: One-Class SVM + PCA, AUROC 0.770.
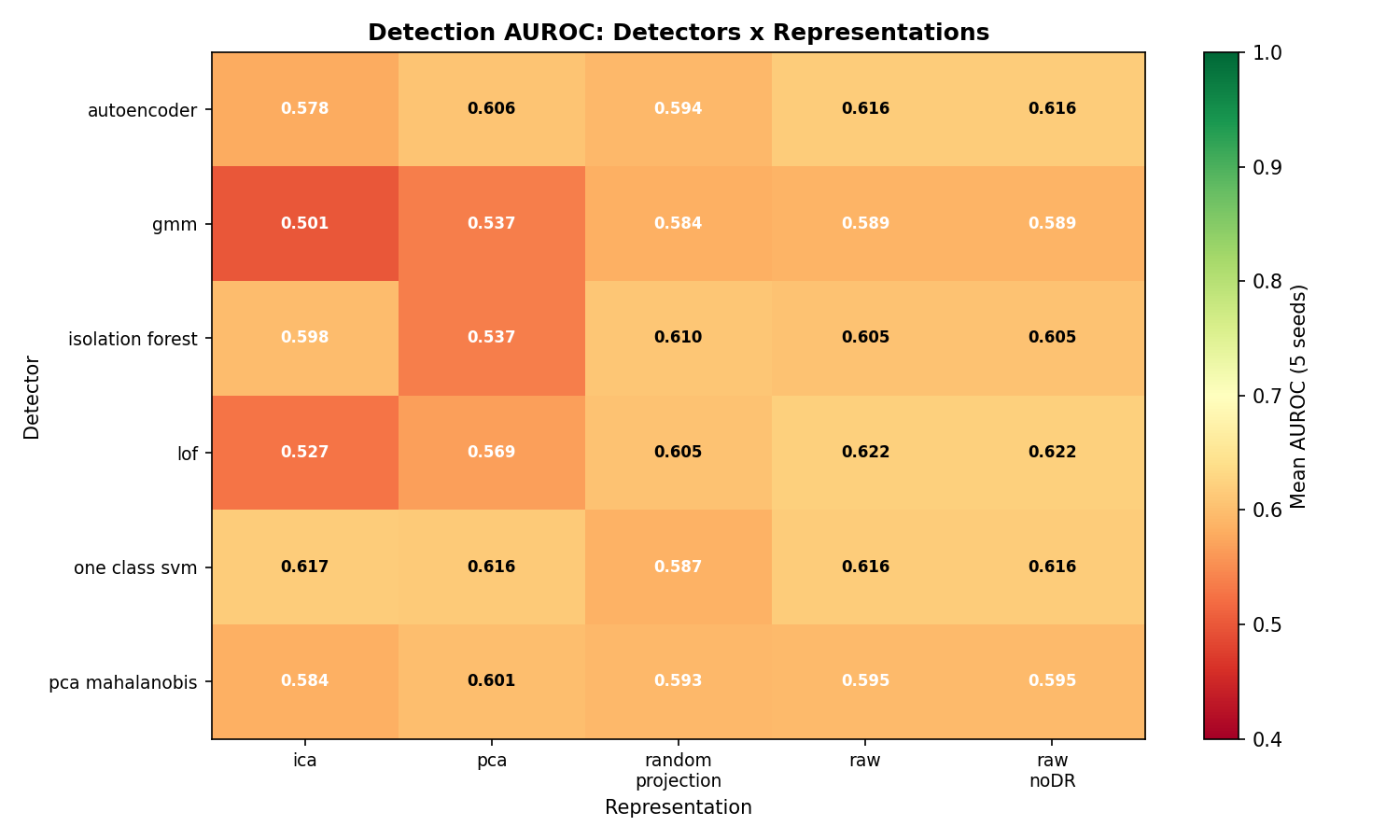
Is AUROC 0.62 impressive? No. But this is a zero-label approach on deliberately subtle (diffuse) synthetic backdoors. The signal is real. On more concentrated backdoors – the kind deployed in practice – detection power should improve, though by how much remains untested.
Result 2: The Surprise – Raw Features Beat Dimensionality Reduction
I expected PCA or ICA to improve detection, just as ICA+GMM improved clustering in my unsupervised learning work. The opposite happened:
| Representation | Mean AUROC |
|---|---|
| Raw | 0.607 |
| Random Projection | 0.596 |
| PCA | 0.578 |
| ICA | 0.568 |
Raw features win for 4 of 6 detectors. Why?
The backdoor signal is diffuse. Training-data poisoning doesn’t create a single anomalous dimension – it creates tiny perturbations spread across many dimensions. PCA concentrates variance in the top components, which are dominated by normal variation. ICA looks for statistically independent sources, but the backdoor signal isn’t independent of normal activations – it’s entangled with them.
Dimensionality reduction throws away exactly the subtle, distributed information you need.
This has a practical lesson: if you’re building anomaly detection for model supply chain security, start with raw features. Don’t assume DR helps just because your feature space is high-dimensional.
Result 3: Contrastive Learning Fails (and Why)
I also tested a SimCLR contrastive learning approach: learn a representation where clean models cluster together, then detect backdoored models as outliers in that embedding space.
| Method | Mean AUROC |
|---|---|
| LOF (raw) | 0.622 |
| SimCLR Contrastive | 0.466 |
Below chance. The contrastive loss never converged to a useful separation (final loss ~2.91 across all seeds).
The failure makes sense in retrospect. SimCLR relies on data augmentations to define “similar” pairs. For images, you crop, rotate, color-jitter. For model fingerprints, there’s no natural augmentation structure. Random noise augmentation doesn’t preserve the semantic relationship between clean model fingerprints.
Making contrastive learning work here requires task-specific augmentations – weight perturbation, layer dropout, activation noise calibrated to the distribution of normal model variation. That’s a research direction, not an off-the-shelf solution.
The ACA Extension: Why Defenders Have the Advantage
In my adversarial IDS project, I developed Adversarial Controllability Analysis (ACA) – classifying every feature by who controls it (attacker vs. defender vs. environment). The key finding there: attackers control 57 of 78 network features, giving them enormous evasion surface.
Behavioral fingerprinting inverts this dynamic:
| Entity | Controls |
|---|---|
| Defender | Reference inputs, detection pipeline, clean model baseline |
| Attacker | Model weights, training data |
| System | Architecture, inference pipeline |
The defender controls the probe. The attacker must create a model that (a) behaves normally on whatever reference inputs the defender chooses, while (b) activating its backdoor only on specific trigger inputs. That’s a much harder evasion problem than manipulating network traffic features.
This is why behavioral fingerprinting is strategically important even with modest current detection rates: the fundamental asymmetry favors the defender.
Trust Score: Making It Actionable
Six detector scores aren’t useful to an engineer deciding whether to deploy a model. I designed a trust score that aggregates them into a single 0-100 risk rating:
- 0-30: Low risk – model behavior consistent with clean models
- 31-60: Medium risk – some anomalies detected, manual review recommended
- 61-100: High risk – significant behavioral anomalies, do not deploy
The ensemble prevents single-detector evasion. An attacker who can fool Isolation Forest still has to fool LOF, One-Class SVM, GMM, the autoencoder, and Mahalanobis distance. Simultaneously.
Honest Limitations
This is a proof-of-concept, not a production detector:
- Synthetic data. The results use synthetic activation vectors, not fingerprints from real backdoored models (BadNets, Blended, WaNet, Clean-label). Real-model validation on TrojAI benchmarks is the next step.
- Small scale. 128 clean reference models per seed. Real deployment needs hundreds to thousands.
- Single poisoning rate. Only 20% backdoor rate tested. Stealthier attacks (1-5%) remain untested.
- No adaptive adversary. Attackers who know behavioral fingerprinting is deployed could optimize evasion.
The Evolution: Static to Behavioral
This project is part of a sequence:
- ModelScan integration – static analysis catches serialization exploits and known patterns
- Behavioral fingerprinting – unsupervised detection catches training-data poisoning that static misses
- [Next] Combined pipeline – layered defense: static scan first (fast, cheap), behavioral scan for models that pass static checks
The same pattern the security industry learned with malware: signatures first, behavioral analysis second, ensemble verdict third. For a hands-on implementation, see the tutorial on detecting backdoored models without labeled examples.
Repository
Code, experiment contract, data contracts, and full results: github.com/rexcoleman/model-behavioral-fingerprint
Built with govML for experiment tracking and reproducibility.
What’s Next
I’m extending this work to real-world model artifacts from TrojAI and Hugging Face Hub — synthetic activation vectors are a starting point, not the destination. The key finding that dimensionality reduction hurts detection needs validation across more model architectures. See the full research report for how this fits into the broader controllability framework.
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.