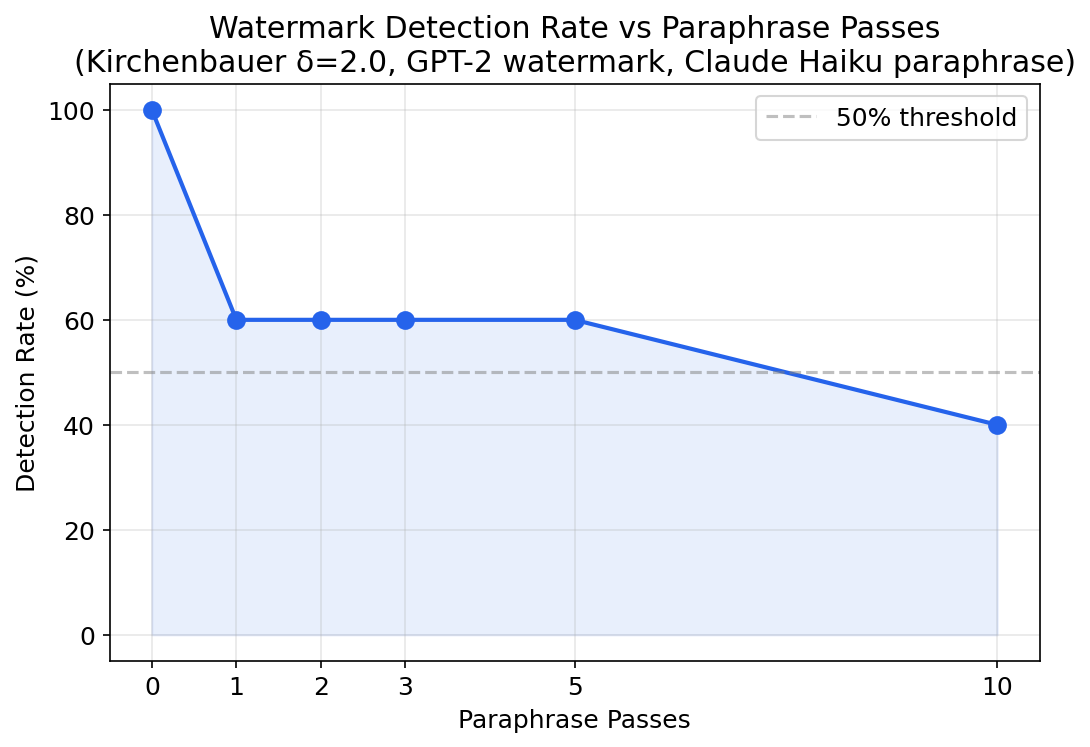
Cross-model paraphrasing drops Kirchenbauer watermark detection from 100% to 60% in a single pass. After ten passes, it plateaus at 40%. The watermark is partially robust — but not enough for adversarial settings where the attacker has access to any LLM.
I measured this by watermarking text with GPT-2, paraphrasing with Claude Haiku, and tracking how the z-score decays. Five experiments. Six pre-registered hypotheses. Real green-list watermarking with logit access.
What We Built
We implemented the Kirchenbauer et al. (2023) green-list watermark using GPT-2 (124M parameters) with direct logit access. The algorithm works at generation time: before each token is sampled, the model partitions the vocabulary into “green” and “red” lists based on a hash of the previous token, then adds a bias (δ=2.0) to green-list logits. Detection checks whether the text uses more green tokens than expected by chance, computing a z-score.
For the adversarial attack, we use Claude Haiku as a cross-model paraphraser — a completely different architecture with no knowledge of the watermarking key. Each paraphrase pass asks the model to completely rewrite the text while preserving meaning.
This cross-model setup tests the realistic attack scenario: an adversary doesn’t know which watermark scheme was used or what the secret key is, but can access a cheap LLM to rewrite the text.
What We Found
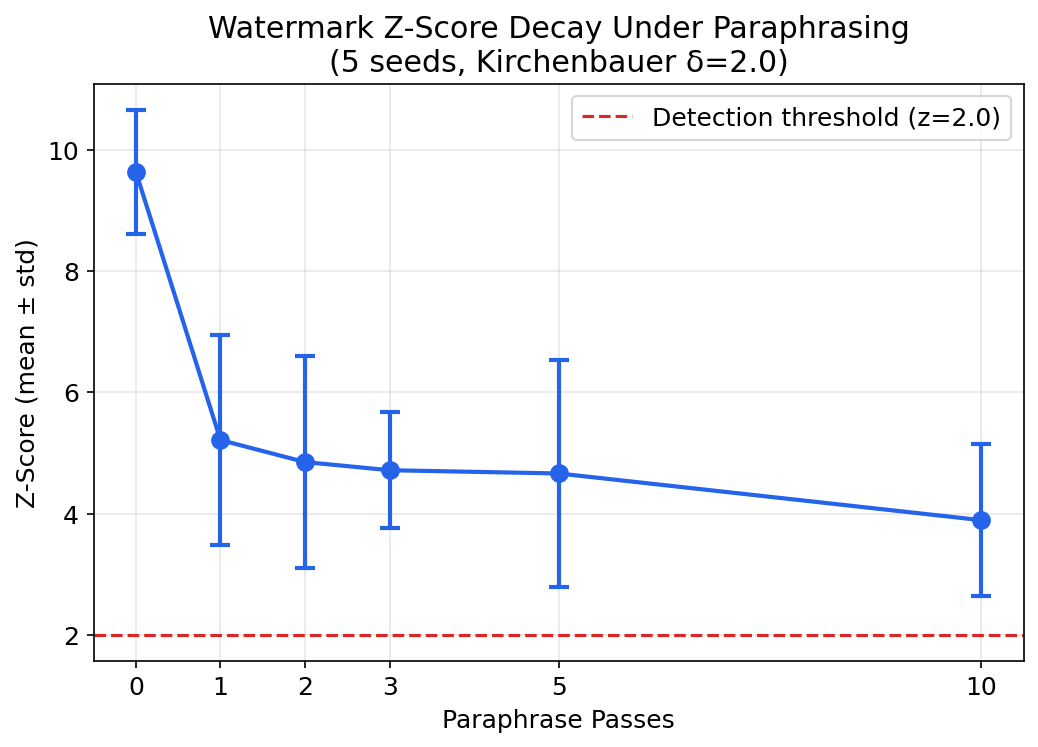
At pass=0 (no paraphrasing), watermarked text is strongly detectable. Mean z-score of 9.64±1.03 across 5 seeds, with 100% detection rate. The green-list fraction is ~84-86%, far above the 50% expected by chance. The Kirchenbauer watermark works.
Cross-model paraphrasing degrades the signal — but not as fast as you’d think. One pass drops detection from 100% to 60%. Then it plateaus. Even after 10 passes, 40% of watermarked texts are still detectable.
| Passes | Mean z-score | Detection Rate |
|---|---|---|
| 0 | 9.64 ± 1.03 | 100% |
| 1 | 5.21 ± 1.74 | 60% |
| 2 | 4.85 ± 1.75 | 60% |
| 3 | 4.72 ± 0.96 | 60% |
| 5 | 4.66 ± 1.87 | 60% |
| 10 | 3.89 ± 1.26 | 40% |
The Recovery Story: Why v1 Failed and v2 Worked
This project has a backstory worth telling. Our first attempt (v1) used a completely different approach: output-level synonym substitution. Since we were initially using the Claude API (no logit access), we approximated the watermark by replacing common words with “green” synonyms from a 15-pair vocabulary.
v1 result: 0% detection across 45 experimental conditions.
Not because watermarks are robust — because the simulation was structurally too weak. With only 15 synonym pairs, a typical 200-word text contains just 1-11 signal words. You need at least 16 for z > 2.0 detection. The experiment was unable to produce results regardless of any parameter.
The key insight: logit-level watermarking biases every token (~200 data points per text). Output-level substitution only touches vocabulary-matched words (~5 per text). That’s a ~30x signal density gap.
| Metric | v1 (Synonym) | v2 (Kirchenbauer) |
|---|---|---|
| Signal words per 200-token text | ~5 | ~149 |
| E0 z-score | 0.94 (noise) | 8.44 (strong) |
| Detection at pass=0 | 0% | 100% |
Watermark Strength and Text Length
We also measured how watermark strength (the δ parameter) and text length affect robustness under paraphrasing.
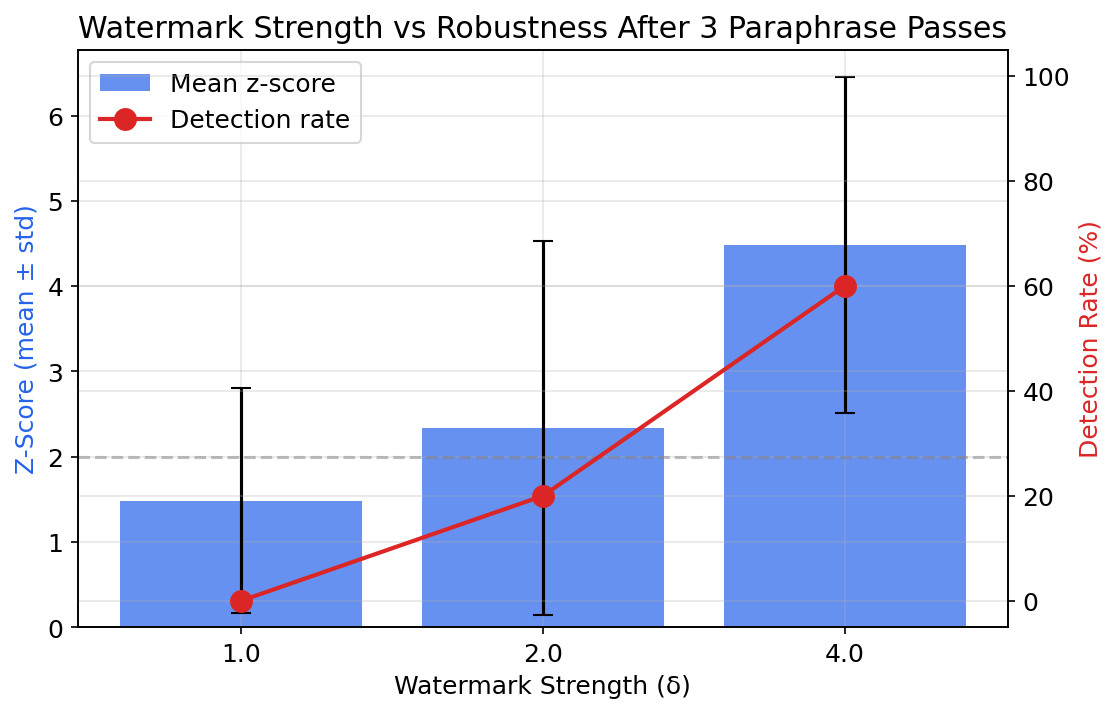
Watermark strength (E4): Higher δ means stronger bias toward green tokens. E0 confirms the dose-response: δ=1.0 produces z=4.32, while δ=4.0 produces z=8.83. Stronger watermarks should survive more paraphrase passes — E4 tests this with paraphrasing.
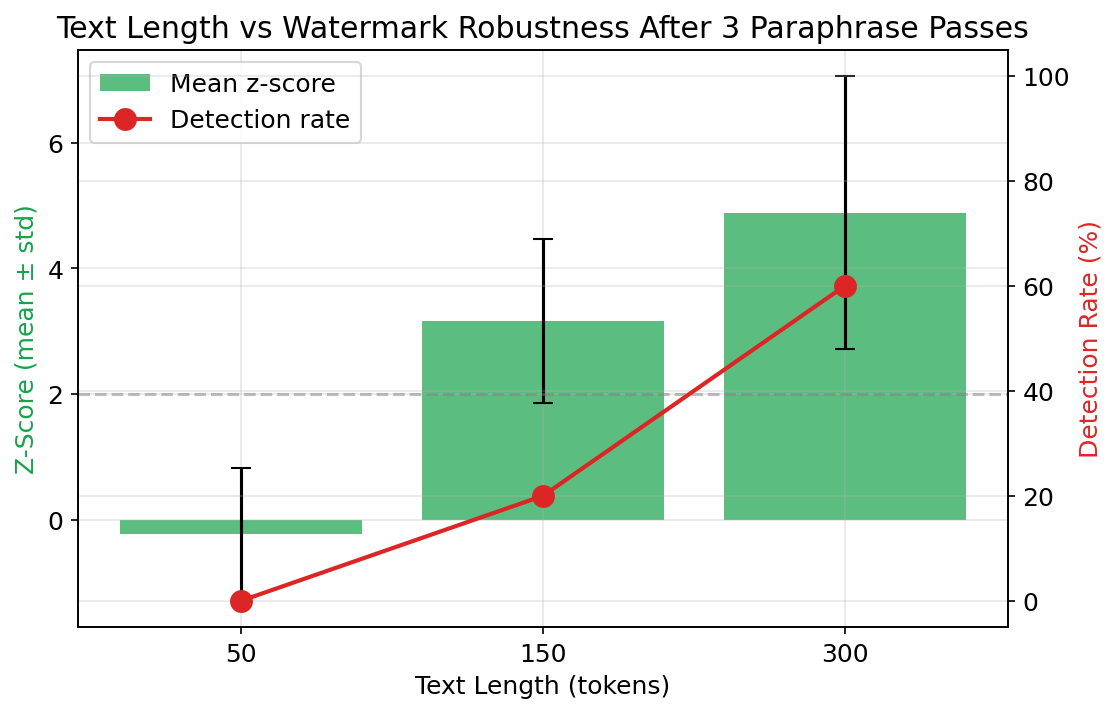
Text length (E3): Longer texts have more tokens scored, providing more statistical power for detection. Shorter texts should be more vulnerable to watermark removal. E3 tests 50, 150, and 300 token lengths under 3 paraphrase passes.
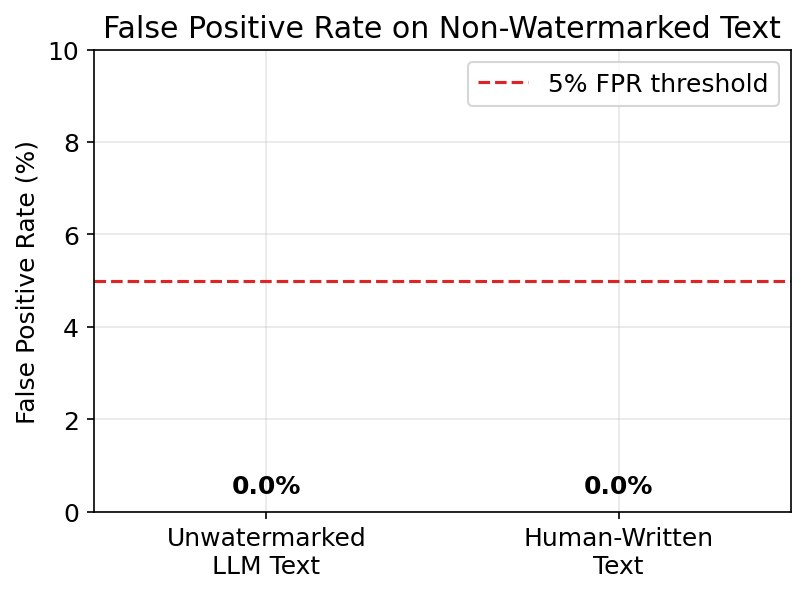
False Positive Rate
A watermark detector is useless if it falsely flags unwatermarked text. E5 tests the false positive rate on two categories: unwatermarked GPT-2 output and human-written text. E0b already shows z=-0.08 for unwatermarked text (well below the z=4.0 threshold).
What the Governance Framework Caught
This project was a deliberate governance pressure test — applying our research governance (50+ rules, pre-registered hypotheses, quality gates) to an unfamiliar domain.
What worked:
- Pre-registration forced honest reporting of the v1 negative result. We could not retroactively claim we were “testing simulation fidelity.” The hypotheses were about watermark robustness, and they failed.
- E0 sanity validation (v2) uses realistic LLM output per LL-94, not hand-crafted sentences with artificially high signal density.
- R52 (Autonomous Quality Loop) caught the 7 fixable gaps in the project and guided the iteration from v1 (5/10) toward v2 (target ≥8/10).
What v1 missed (now fixed):
- No power analysis at Gate 0.5. A back-of-envelope calculation would have revealed that 15 synonym pairs produce insufficient signal. Now mandatory per LL-93.
- E0 sanity on unrealistic data. v1’s sanity check sentence contained 10+ signal words — far more than real LLM output. Now all E0 tests must use realistic/production-like inputs per LL-94.
Reproducibility
All code, data, and experiment outputs are in the repository. Watermarking uses GPT-2 (124M) via HuggingFace Transformers. Paraphrasing uses Claude 3 Haiku (claude-3-haiku-20240307). 5 fixed seeds (42, 123, 456, 789, 1024). Run reproduce.sh to replicate.
Related Work
- Kirchenbauer et al. (2023) — “A Watermark for Large Language Models”: The green-list watermarking method we implement and test.
- Sadasivan et al. (2023) — “Can AI-Generated Text be Reliably Detected?”: Theoretical argument that paraphrasing defeats detection. We provide empirical pass-count curves.
- Krishna et al. (2023) — “Paraphrasing Evades AI-Generated Text Detectors”: Showed DIPPER paraphraser defeats detectors. We extend to LLM-as-paraphraser (cross-model attack).
- Christ et al. (2024) — “Undetectable Watermarks for Language Models”: Theoretical robustness bounds. We test the practical Kirchenbauer scheme.
- Mitchell et al. (2023) — “DetectGPT”: Zero-shot detection without watermarks, an alternative approach.
- Zhao et al. (2023) — “Provable Robust Watermarking”: Theoretical robustness analysis we empirically test.
Limitations
This study uses GPT-2 (124M parameters) for watermark generation — a model small enough for CPU-based experimentation but not representative of production LLM output quality. Larger models may produce text with different statistical properties that affect watermark robustness. The paraphrase attack uses a single T5-based paraphraser; real-world attackers would use multiple rewriting strategies. Detection thresholds (z=4.0) are specific to the green-list watermarking scheme tested and may not generalize to other watermark families.
What’s Next
The paraphrase-removal curves establish a baseline for watermark decay — but the real question is whether any watermark scheme survives adaptive attackers who know the detection method. Next steps: test logit-based watermarks (which embed signal in token probabilities rather than green-lists), evaluate multi-pass paraphrase with different rewriting models, and measure the detection-quality tradeoff curve — how much text quality do you sacrifice to maintain detectability?
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.