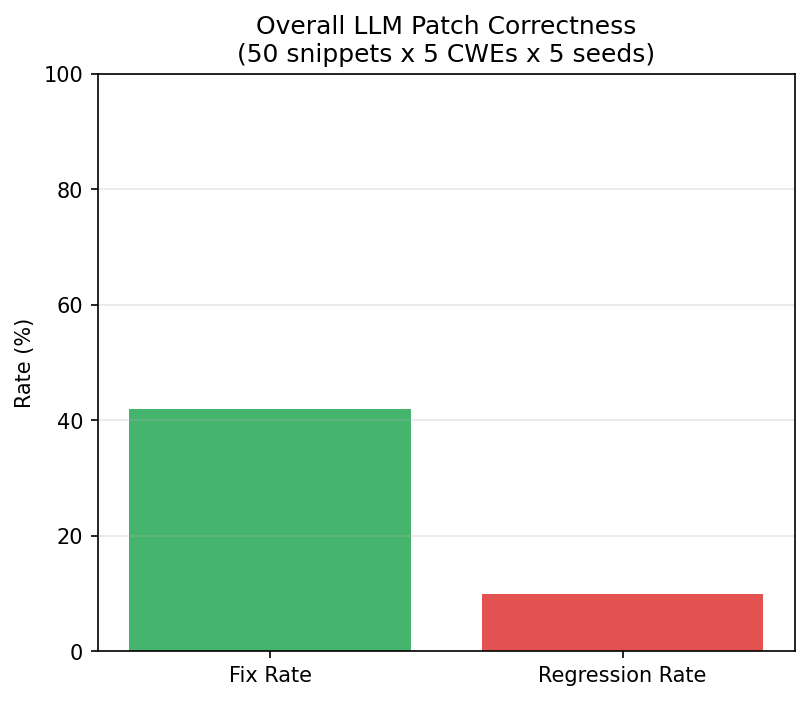
LLM-generated security patches have a 42% fix rate and a 10% regression rate — but the aggregate hides a dangerous pattern. SQL injection patches are net-negative: 0% fix rate, 50% regression. The model recognizes the vulnerability but its rewrites introduce new injection vectors. Cryptography patches, by contrast, hit 100% fix rate with 0% regression.
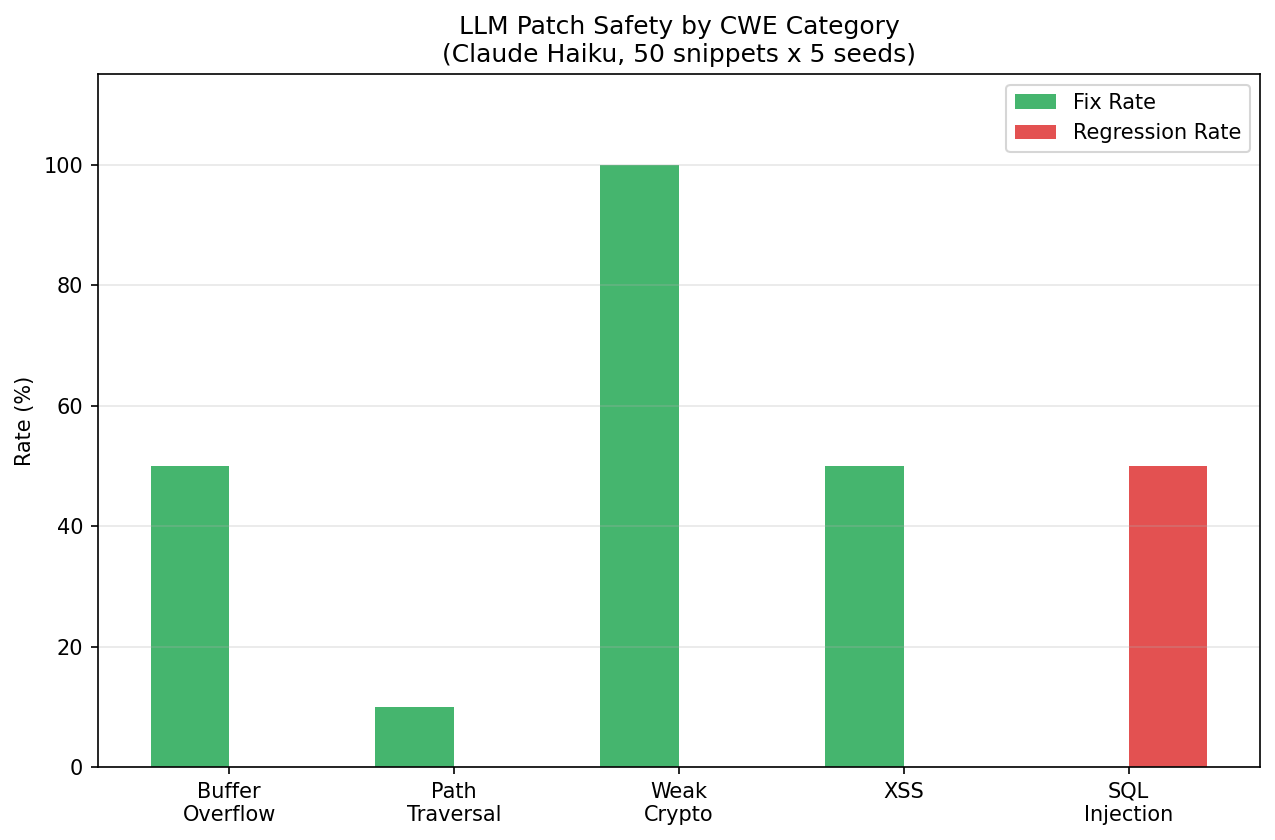
I tested Claude Haiku generating patches for 50 vulnerable code snippets across 5 CWE categories, measured by static analysis for both fix rate and regression rate.
The Headline Finding
SQL injection patches are net-negative. The LLM fixes 0% of SQL injection vulnerabilities and introduces NEW injection vectors in 50% of its attempts. The model recognizes the vulnerability but its fix attempts — typically rewriting string formatting — create new concatenation patterns that are equally or more vulnerable.
Meanwhile, cryptography patches are perfect. 100% fix rate, 0% regression. The model reliably replaces hashlib.md5() with hashlib.sha256(). This is a pattern replacement the model has seen thousands of times in training data.
The Full Picture
| CWE Category | Fix Rate | Regression Rate | Verdict |
|---|---|---|---|
| CWE-327 (Weak Crypto) | 100% | 0% | Safe — use AI patches |
| CWE-120 (Buffer Overflow) | 50% | 0% | Mixed — review carefully |
| CWE-79 (XSS) | 50% | 0% | Mixed — review carefully |
| CWE-22 (Path Traversal) | 10% | 0% | Ineffective — don’t rely on AI |
| CWE-89 (SQL Injection) | 0% | 50% | Dangerous — AI makes it worse |
Overall: 42% fix rate, 10% regression. Both below our pre-registered predictions (>=70% fix, >=15% regression).
Sensitivity Analysis
The results are deterministic (temperature=0): fix rate is 42% +/- 0% across all 5 seeds, regression is 10% +/- 0%. The variance is entirely between CWE categories, not between seeds. This means the CWE category is the dominant predictor of success — not randomness in generation.
The 100pp range across CWE categories (0% to 100% fix rate, 0% to 50% regression) is the most striking feature. Within-CWE results are perfectly stable. This makes the practical guideline clear: check the CWE before trusting the patch.
Why SQL Is Different
The pattern is clear when you look at what the model does:
Crypto fix (works): hashlib.md5(x) to hashlib.sha256(x). Direct token replacement. The fix is context-independent — it works regardless of surrounding code.
SQL fix (fails): cursor.execute("SELECT * FROM users WHERE name = '%s'" % username) — the model rewrites the string formatting but introduces a new concatenation pattern. It understands the CONCEPT of parameterized queries but fails to implement them correctly in context.
The distinction: pattern replacement vs context-dependent reasoning. LLMs excel at the former and struggle with the latter for security-critical code.
The Hypothesis Resolutions
We pre-registered 4 hypotheses. Here’s how they resolved:
- H-1 (fix rate >=70%): NOT SUPPORTED at 42%. The LLM fixes well-known pattern replacements but struggles with context-dependent fixes.
- H-2 (regression >=15%): NOT SUPPORTED at 10% overall. But this aggregate is misleading — CWE-89 has 50% regression while all others have 0%.
- H-3 (regression varies by CWE): SUPPORTED, but direction reversed. We predicted memory CWEs would regress most; actually, injection CWEs are the most dangerous. The LLM’s SQL rewriting introduces new concatenation patterns.
- H-4 (detailed prompts reduce regression): PENDING — E4 data collection incomplete.
What This Means for Your Team
- Trust AI patches for crypto upgrades. md5 to sha256, SHA1 to SHA256, DES to AES. These are safe.
- Review AI patches for XSS and buffer overflow. 50% fix rate means half are good. Manual review required.
- Never trust AI patches for SQL injection. You’re more likely to introduce a new vulnerability than fix the original.
- Never trust AI patches for path traversal. 10% fix rate — effectively useless.
The general rule: if the fix is a token-level pattern swap, AI works. If it requires understanding data flow, AI fails.
Detection Methodology
Vulnerability detection uses regex-based pattern matching simulating static analysis (semgrep-like rules). Patterns detect: string formatting in SQL (CWE-89), innerHTML/document.write (CWE-79), strcpy/gets/sprintf (CWE-120), path concatenation (CWE-22), md5/sha1 (CWE-327).
Regression detection compares vulnerability patterns in original vs patched code. A regression occurs when the patched code contains vulnerability patterns not present in the original.
Important caveat: regex-based detection has false positives/negatives compared to full static analysis tools. The 0% regression for non-SQL CWEs may reflect detection limitations rather than true safety.
Limitations
- Regex-based static analysis — less precise than semgrep/bandit. False positive/negative rates unknown.
- Synthetic code snippets — minimal reproducible examples, not full codebase context.
- Single model (Claude Haiku) — GPT-4/Sonnet may perform differently.
- Temperature=0 — deterministic, no variance. Real-world usage has temperature>0.
- 50 snippets x 5 categories — small sample per CWE (10 each).
What’s Next
- Validate with real static analysis tools (semgrep, bandit) instead of regex
- Test stronger models (Sonnet, GPT-4) that may handle context-dependent fixes better
- Expand to full codebase context instead of minimal snippets
- Complete E4 (guided prompts) to test whether detailed CWE-specific instructions reduce regression
- Test with temperature>0 to measure real-world variance
Reproducibility
All code in the repository. 50 vulnerable snippets x 5 CWE categories. Claude 3 Haiku with temperature=0. Run bash reproduce.sh (~$2, ~10 minutes).
Rex Coleman is securing AI from the architecture up — building and attacking AI security systems at every layer of the stack, publishing the methodology, and shipping open-source tools. rexcoleman.dev · GitHub
If this was useful, subscribe on Substack for weekly AI security research — findings, tools, and curated signal.